




Apprentissage par renforcement dans la gestion des risques des projets de construction pharmaceutique
Points forts
- Nous avons examiné 86 études sur l’apprentissage par renforcement (RL) dans les projets de construction pharmaceutique entre 2016 et 2025.
- Identification des types d’algorithmes d’apprentissage par renforcement et des sujets de recherche les plus influents.
- Nous avons décrit les principes, les avantages et les inconvénients de six algorithmes d’apprentissage par renforcement.
- Mise en lumière des principaux défis auxquels est confrontée la recherche en apprentissage automatique dans les projets de construction pharmaceutique.
- Stratégies de diffusion spécifiques et orientations futures de la recherche indiquées.
Résumés
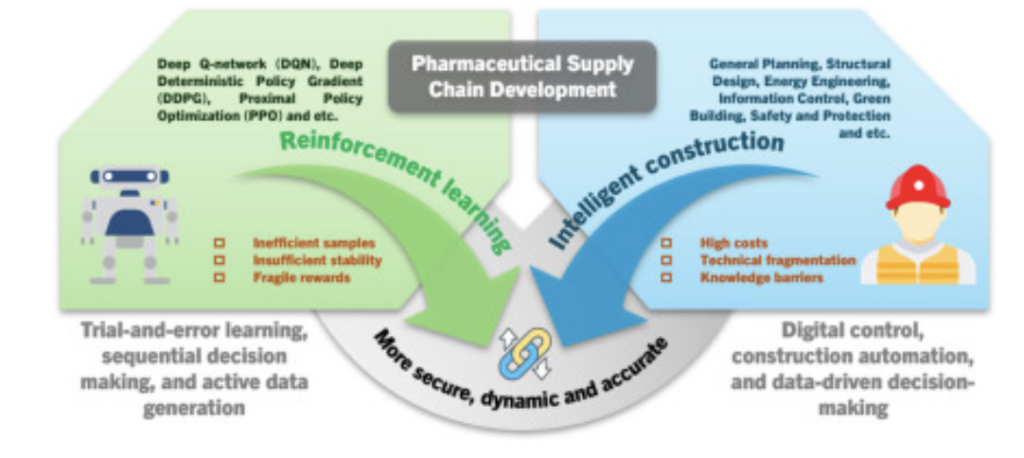
La construction intelligente d’installations pharmaceutiques est confrontée à des risques dynamiques et non linéaires, et les méthodes de gestion traditionnelles peinent à répondre aux exigences élevées de réactivité et de conformité en temps réel. Or, les recherches existantes sur l’apprentissage par renforcement (AR) dans ce domaine manquent encore d’une architecture d’application systématique et de considérations relatives à la gouvernance industrielle. Par conséquent, cet article examine les applications pratiques de six algorithmes – Deep Q-Network (DQN), Deep Deterministic Policy Gradient (DDPG) et Proximity Policy Optimization (PPO) – dans les domaines de la sécurité de la construction, du contrôle de la température, de la planification des ressources et de l’optimisation automatisée des équipements, validant ainsi le potentiel de l’apprentissage par renforcement pour gérer efficacement les risques dynamiques grâce à un apprentissage adaptatif. Parallèlement, cet article identifie avec précision les principaux obstacles rencontrés dans les applications actuelles : l’écart de fidélité entre l’environnement de simulation et la réglementation médicale réelle, l’absence de procédures de déploiement standardisées pour l’apprentissage par renforcement et l’ambiguïté entre l’autorité de décision algorithmique et la responsabilité de supervision humaine. Pour remédier à ces problèmes, cet article présente un système de simulation d’environnement haute fidélité intégrant de multiples technologies, un cadre d’application d’apprentissage par renforcement standardisé et un système de gouvernance clair des droits et responsabilités, fournissant un soutien théorique crucial et des voies pratiques pour la construction d’un paradigme fiable et efficace de gestion des risques liés à la construction d’installations pharmaceutiques.
Résumé graphique
Mots clés
- Apprentissage par renforcement
- projets de construction pharmaceutiques
- Gestion des risques
- Gradient de politique déterministe profond
- Optimisation de la politique proximale
- Réseau Q profond
1. Introduction
L’industrie pharmaceutique est un secteur vital de l’économie nationale, du bien-être de la population et de la sécurité nationale. Selon les dernières données du ministère de l’Industrie et des Technologies de l’information, depuis le début du 14e plan quinquennal, l’industrie pharmaceutique chinoise a enregistré un taux de croissance annuel moyen de 9,3 % pour son chiffre d’affaires principal, de 11,3 % pour ses bénéfices totaux et de plus de 20 % pour ses investissements en R&D [ 1 ]. Les projets de construction d’installations pharmaceutiques constituent le socle matériel du développement durable de l’industrie, garantissant la sécurité d’approvisionnement en médicaments et permettant l’itération et la modernisation technologiques. Ces projets présentent souvent des caractéristiques distinctes dans leurs processus et méthodologies de mise en œuvre [ 2 ]. Contrairement aux projets de construction classiques, leur objectif principal dépasse la simple construction d’un espace physique ; il s’agit fondamentalement d’établir un environnement de production propre, hautement contrôlé, vérifiable et conforme aux BPF (Bonnes Pratiques de Fabrication) [ 3 ]. Par conséquent, elle dépasse largement le cadre de la construction et de l’installation de bâtiments conventionnels, intégrant pleinement des technologies complexes de salles blanches (telles que les systèmes CVC et les systèmes d’eau purifiée), des schémas de flux de processus rigoureux et des activités de validation exhaustives. Sa gestion des risques est constamment confrontée à des défis considérables posés par des environnements dynamiques, de multiples contraintes et des événements imprévus, même rares. Les approches traditionnelles de gestion des risques, souvent fondées sur une expérience statique et des règles prédéfinies, sont fréquemment inadéquates et rigides face aux incertitudes constantes qui surgissent tout au long du cycle de vie d’un projet [ 4 , 5 ]. Par exemple, les approches traditionnelles d’apprentissage automatique (AA) se révèlent souvent inadaptées aux scénarios de risques dynamiques, multidimensionnels et non linéaires en raison de leur capacité limitée d’interaction soutenue avec l’environnement [ 6 , 7 ].Ces dernières années, les avancées en intelligence artificielle (IA), et notamment en apprentissage par renforcement (AR), avec son paradigme central distinctif d’« agents apprenant de manière autonome des stratégies optimales grâce à l’interaction avec leur environnement », ont ouvert de nouvelles perspectives pour relever ce défi [ 8 ]. L’AR, en tant que classe de techniques de prise de décision autonomes basées sur le processus de décision markovien, optimise les stratégies dans des environnements dynamiques grâce au mécanisme d’« essais et erreurs avec rétroaction », offrant ainsi une approche inédite pour résoudre le problème multidimensionnel de la gestion intelligente des risques dans la construction [ 9 ]. Comparé aux méthodes traditionnelles, l’AR présente des avantages uniques dans trois domaines. Premièrement, il ne nécessite pas la définition de règles heuristiques et d’itérations distinctes pour les autres tâches de construction ; il apprend automatiquement diverses stratégies d’optimisation lors de l’entraînement et de la simulation [ 56 ]. Deuxièmement, sa capacité de représentation efficace des espaces d’états de grande dimension a permis de réduire considérablement la dépendance aux connaissances et au jugement d’experts dans des processus tels que la modélisation des informations du bâtiment (BIM) [ 50 ]. Plus important encore, son cadre offre une aide à la décision distribuée pour les systèmes collaboratifs tels que les parcs de grues à tour et les flottes de robots, en se caractérisant par l’auto-apprentissage, la robustesse et l’adaptabilité [ 162 ]. Par exemple, Han et al. [ 10 ] ont développé une méthode décentralisée de planification modulaire de la rénovation d’hôpitaux basée sur des algorithmes d’apprentissage par renforcement profond à mémoire étendue. Guerrero et al. [ 11 ] ont développé un système d’aide à la décision pour la conception de bâtiments de santé, basé sur le raisonnement à partir de cas et l’apprentissage par renforcement, démontrant une grande efficacité dans la détection des défauts et des erreurs. Ainsi, comme le montre la figure 1 , au cours de la dernière décennie, le nombre d’articles sur l’apprentissage par renforcement a connu une croissance exponentielle, passant de 2 268 en 2015 à 35 488 en 2024. Cette tendance s’observe également pour le nombre annuel de publications sur l’apprentissage par renforcement dans le secteur de la construction et la gestion des risques.
Fig. 1. Tendances annuelles des publications en apprentissage par renforcement.
2. Principe de base de l’apprentissage par renforcement
Comme indiqué sur la figure 2 , le processus de décision markovien (MDP) est au cœur de l’apprentissage par renforcement (RL). En RL, un agent apprend en interagissant avec son environnement, cherchant à prendre des décisions basées sur l’état de ce dernier afin de maximiser les récompenses à long terme. Le MDP fournit un cadre pour modéliser la relation entre l’intelligence et l’environnement dans les problèmes d’apprentissage par renforcement, aidant ainsi à décrire comment prendre des décisions optimales dans des problèmes de décision dynamiques et séquentiels [ 82 ]. Le MDP est composé d’un quintuplet.oùest l’espace d’état,est l’espace d’action,est la probabilité de transfert d’état,est la fonction de récompense, et γ est le facteur d’actualisation. L’objectif est de trouver une politique optimalequi maximise la récompense cumulative à long terme et satisfait l’équation de Bellman [ 83 ] :
Fig. 2. Apprentissage par renforcement avec processus de chaîne de Markov.
3. Méthodes et matériaux
3.1 . Méthodes de recherche
La présentation de cette revue systématique suit les critères de la déclaration PRISMA (Preferred Reporting Items for Systematic Reviews and Meta-Analyses). Elle vise à aider les auteurs à présenter de manière transparente la motivation, les méthodes et les résultats de leurs revues systématiques, améliorant ainsi la transparence et la reproductibilité de leurs études. Par ailleurs, elle a mis en œuvre une méthodologie de recherche hybride combinant bibliométrie et analyse de contenu.
3.2 . Matériel de recherche
Le processus de recherche, de collecte et d’analyse des données de cette étude est résumé dans la figure 3. Premièrement, les bases de données Web of Science (WoS) et Scopus, reconnues par de nombreuses études comme étant parfaitement adaptées à l’analyse d’articles sur l’ingénierie et les technologies innovantes, ont été sélectionnées comme sources de recherche bibliographique. Deuxièmement, comme indiqué dans le tableau 1 , des mots-clés tels que « Installation pharmaceutique », « Risque de sécurité » et « Apprentissage par renforcement Q » ont été utilisés. Les codes de recherche spécifiques à chaque base de données sont listés dans le tableau 2. Après une première sélection, 75 références ont été obtenues de WoS et 98 de Scopus. Ces articles ont ensuite été examinés afin d’éliminer les références non pertinentes et les doublons, sur la base des titres et des résumés, ce qui a permis de retenir 106 documents. Troisièmement, le texte intégral a été évalué selon les critères suivants : (1) la gestion des risques devait être directement ou indirectement liée à la construction ; (2) les études ne présentant qu’une brève introduction à l’apprentissage par renforcement Q ont été exclues. (3) Conformément à la norme ISO 31000:2018, les études ne comportant aucune étape de gestion des risques (identification, analyse, évaluation et suivi) doivent être exclues. Au final, 86 documents ont été retenus pour l’analyse ultérieure.
Tableau 1. Mots -clés utilisés pour la recherche bibliographique.
| Domaine de recherche | Objet | Types d’algorithmes |
|---|---|---|
| installation pharmaceutique | Risque pour la sécurité | Apprentissage par renforcement (Q-Learning) |
| Réseau Q profond | ||
| Bâtiment pharmaceutique | Risque pour la santé | Sarsa |
| acteur-critique | ||
| Optimisation de la politique proximale | ||
| construction intelligente | Risque pour la sécurité | Gradient de politique déterministe profond |
| Apprentissage par renforcement |
Tableau 2. Code de récupération utilisé pour la recherche bibliographique.
| Bases de données | Récupérer le code |
|---|---|
| Scopus | TITLE-ABS-KEY (« Installation pharmaceutique » OU « Bâtiment pharmaceutique » OU « Construction intelligente ») ET (« Risque pour la sécurité » OU « Risque pour la santé » OU « Risque de sûreté ») ET (« Apprentissage par renforcement » OU « Réseau de neurones profond Q » OU « Sarsa » OU « Apprentissage acteur-critique » OU « Optimisation de politique proximale » OU « Gradient de politique déterministe profond » OU « Apprentissage par renforcement ») |
| Web of Science | TS= (Installation pharmaceutique OU Bâtiment pharmaceutique OU Construction intelligente) ET TS= (Risque pour la sécurité OU Risque pour la santé OU Risque pour la sûreté) ET TS= (Apprentissage par renforcement Q OU Réseau Q profond OU Sarsa OU Apprentissage acteur-critique OU Optimisation de politique proximale OU Gradient de politique déterministe profond OU Apprentissage par renforcement) |
4.1 . Analyse de la cooccurrence des mots clés
Dans cet article, nous effectuons une analyse bibliométrique basée sur l’algorithme de Leiden pour la cooccurrence de mots-clés, à l’aide du logiciel Bibliometrix®. L’algorithme de Leiden est un algorithme de découverte de communautés amélioré, conçu pour optimiser le degré de modularité et pallier certaines lacunes de l’algorithme de Louvain. Sa formule principale est la suivante :

Les paramètres quantitatifs par défaut du modèle de Leiden sont présentés dans
le Tableau 3. Le modèle se divise en trois phases principales : déplacement local des nœuds, raffinement des partitions et agrégation des réseaux. Les principales étapes et formules du modèle de Leiden sont les suivantes : (1) Déplacement local des nœuds : une file d’attente contenant tous les nœuds est initialisée. Le premier nœud de la file est ensuite traité et déplacé vers une nouvelle communauté si ce déplacement améliore le score de la fonction de qualité. Si un nœud est déplacé, ses voisins sont parcourus et ajoutés à la file d’attente aux nœuds n’appartenant pas à la nouvelle communauté et qui ne sont pas déjà présents. Ces étapes sont répétées jusqu’à ce que la file d’attente soit vide. (2) Raffinement des partitions : initialement, chaque nœud représente une communauté. Les nœuds appartenant à une seule communauté sont ensuite fusionnés avec d’autres communautés, à condition que les deux communautés fusionnées le soient. Enfin, une communauté dont le score de qualité est supérieur à 0 est sélectionnée aléatoirement pour la fusion. (3) Agrégation du réseau : les communautés obtenues lors du raffinement des partitions sont fusionnées pour créer un nouveau réseau agrégé.
Tableau 3. Paramètres du modèle de Leiden.
| Opacité | Taille de l’étiquette | Taille du bord | force de répulsion | Nombre minimal d’arêtes |
|---|---|---|---|---|
| 0,7 | 3 | 5 | 0,1 | 2 |
Les résultats du regroupement sont présentés dans la figure 4 et le tableau 4 , et répartis en quatre groupes. Le groupe 1 met l’accent sur le comportement, le modèle et le cadre comme éléments centraux de la recherche appliquée en apprentissage par renforcement. Ce groupe reflète les principales applications de l’apprentissage par renforcement dans la gestion des risques liés à la construction d’installations pharmaceutiques, en se concentrant principalement sur la modélisation du comportement du personnel de construction en salle blanche, le respect des procédures d’installation des équipements et la construction d’un cadre de prise de décision dynamique pour garantir la conformité aux Bonnes Pratiques de Fabrication (BPF). Les mots-clés « comportement », « modèle » et « cadre » présentent des valeurs élevées de médiation et de PageRank, indiquant que ces concepts sont essentiels pour relier les algorithmes théoriques aux besoins spécifiques de l’industrie pharmaceutique. Les algorithmes d’apprentissage par renforcement ont obtenu des résultats significatifs en matière de garantie de la qualité de la construction et de prévention des risques de contamination, en capturant l’impact dynamique du comportement du personnel de construction sur les paramètres environnementaux des salles blanches et en optimisant la séquence des activités clés telles que le soudage des tuyaux et le transfert de la zone aseptique. De plus, la corrélation entre « performance » et « algorithme » indique que la recherche se concentre désormais sur l’amélioration d’aspects spécifiques de la performance, tels que l’efficacité de la mise en service des lignes de production pharmaceutique et la réduction des cycles de validation, plutôt que sur le développement d’algorithmes généraux. Les recherches futures devraient viser à élaborer un cadre de modélisation général intégrant des facteurs externes comme le « climat » (par exemple, l’impact des fluctuations de température et d’humidité extérieures sur les environnements intérieurs propres), afin de concevoir des systèmes de prédiction et de gestion des risques plus robustes et adaptés aux installations pharmaceutiques de haute qualité.
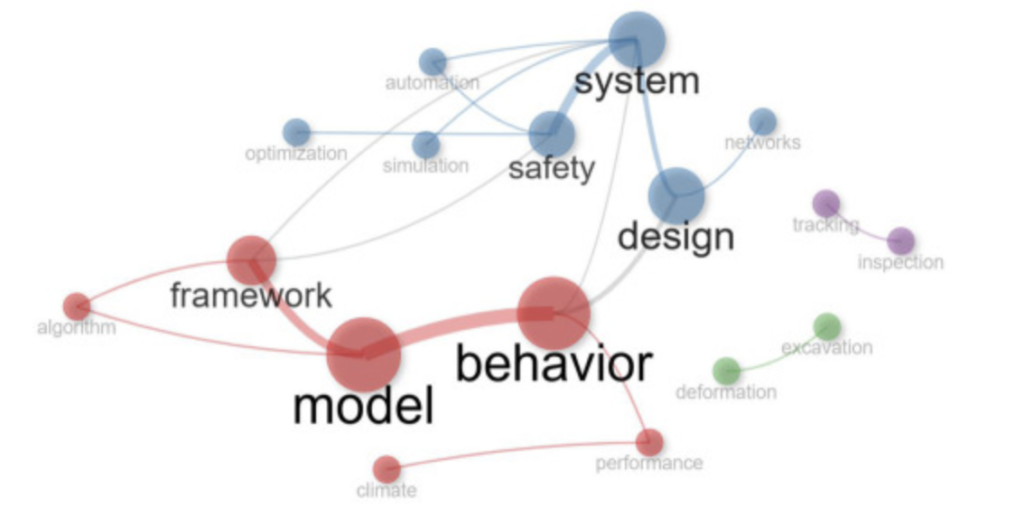
Fig. 4. Réseau de cooccurrence de mots clés.
Tableau 4. Résultats de l’analyse de regroupement.
| Nœud | Grappe | Intermédiarité | Proximité | PageRank |
|---|---|---|---|---|
| comportement | 1 | 24,92429792 | 0,047619048 | 0,098891076 |
| modèle | 1 | 6,928571429 | 0,038461538 | 0,085858473 |
| cadre | 1 | 9,075702076 | 0,041666667 | 0,079130819 |
| performance | 1 | 11 | 0,033333333 | 0,047488217 |
| algorithme | 1 | 0 | 0,032258065 | 0,035544805 |
| climat | 1 | 0 | 0,024390244 | 0,029006022 |
| conception | 2 | 11 | 0,041666667 | 0,071218942 |
| système | 2 | 30,76373626 | 0,052631579 | 0,123630221 |
| sécurité | 2 | 12,30769231 | 0,041666667 | 0,086183817 |
| optimisation | 2 | 0 | 0,028571429 | 0,023474778 |
| simulation | 2 | 0 | 0,033333333 | 0,022834954 |
| automation | 2 | 0 | 0,035714286 | 0,037486203 |
| réseaux | 2 | 0 | 0,028571429 | 0,023957555 |
| déformation | 3 | 0 | 1 | 0,058823529 |
| excavation | 3 | 0 | 1 | 0,058823529 |
| inspection | 4 | 0 | 1 | 0,058823529 |
| suivi | 4 | 0 | 1 | 0,058823529 |
5. Discussions
5.1 . Défis liés à l’apprentissage par renforcement
5.1.1 . Difficultés liées à la collecte de données et à la modélisation environnementale
L’apprentissage par renforcement appliqué aux scénarios de construction repose sur une grande quantité de données état-action-récompense. Or, les événements à haut risque (effondrements, chutes, etc.) sont très rares en réalité, ce qui engendre une grave pénurie d’exemples de risques critiques. Par ailleurs, le déploiement de capteurs est limité par des environnements difficiles (poussière, vibrations, etc.), l’enregistrement manuel est sujet à des biais subjectifs et les dispositifs portables peuvent nuire à la sécurité des opérations. Plus grave encore, la spécificité de chaque projet rend difficile la migration des données, obligeant chaque nouveau chantier à collecter des données à partir de zéro. Ce « démarrage à froid » limite considérablement l’utilité de l’apprentissage par renforcement dans les scénarios de construction. Les risques résultent souvent de l’interaction de facteurs mécaniques, chimiques, humains et autres facteurs multidomaines (effets combinés du vent, des vibrations structurelles et de la manipulation par les travailleurs, par exemple). Les méthodes existantes de modélisation des environnements d’apprentissage par renforcement peinent à reproduire fidèlement ces interactions multiphysiques. Par exemple, les modèles simplifiés peuvent omettre des mécanismes de risque clés (comme l’effet des vibrations sur le desserrage des boulons), tandis que les simulations numériques haute fidélité (comme l’analyse par éléments finis) sont gourmandes en temps de calcul et ne permettent pas de satisfaire aux interactions en temps réel requises pour l’apprentissage par renforcement. Ce paradoxe entre « fidélité de modélisation et efficacité de calcul » rend l’environnement d’entraînement fondamentalement différent du scénario réel.De nombreux chercheurs ont proposé la génération de données synthétiques, utilisant la modélisation physique, la simulation procédurale ou les modèles génératifs (par exemple, les GAN) pour créer des ensembles de données diversifiés et réalistes [
152 ]. D’autres ont avancé que l’apprentissage conjoint, où l’entraînement décentralisé du modèle est réalisé entre différents chantiers ou entreprises sans échange des données originales, est plus efficace, améliorant ainsi les capacités de généralisation tout en protégeant la confidentialité des données. En matière de modélisation environnementale, l’environnement de la construction intelligente est très dynamique et présente des interactions physiques complexes, ce qui rend la modélisation précise extrêmement difficile. De plus, les perturbations externes fréquentes (changements météorologiques, accidents imprévus) rendent la dynamique environnementale difficile à prévoir, tandis que l’observabilité partielle (par exemple, l’état caché des travaux) affaiblit la fiabilité du modèle.
5.1.2 . Absence de cadre de référence pour les paradigmes d’application
Actuellement, il n’existe pas de cadre de référence unifié pour l’application de l’apprentissage par renforcement (AR) à la gestion des risques dans le secteur de la construction, ce qui engendre un décalage important entre la recherche théorique et la pratique de l’ingénierie. La communauté académique privilégie les indicateurs de performance des algorithmes (tels que la vitesse de convergence et le rendement), tandis que le domaine de l’ingénierie met davantage l’accent sur l’interprétabilité, la redondance de sécurité et la conformité . Ce décalage dans les critères d’évaluation explique pourquoi de nombreux algorithmes d’AR, bien que performants dans les publications scientifiques, sont difficiles à intégrer dans les systèmes de gestion de l’ingénierie. Plus critique encore, les décisions relatives à la sécurité sur les chantiers nécessitent souvent l’intégration des normes sectorielles (par exemple, les normes OSHA) et de l’expertise, or les cadres d’AR existants ne disposent pas de mécanismes permettant d’intégrer systématiquement ces connaissances préalables, ce qui conduit à des conflits entre les décisions algorithmiques et l’intuition des ingénieurs.
6. Conclusion
Cet article explore de manière systématique les progrès de la recherche, les principaux défis et les stratégies d’amélioration de l’apprentissage par renforcement dans la gestion des risques liés à la construction d’installations pharmaceutiques. Les recherches montrent que, malgré les premiers succès obtenus par cette technologie dans la surveillance de la sécurité des chantiers et la planification des ressources, son application à des scénarios à haut risque, tels que la construction d’usines pharmaceutiques de haute technologie, de salles blanches et de laboratoires, reste encore à ses débuts. La recherche actuelle présente trois limitations majeures : premièrement, les exigences spécifiques en matière de contrôle de la biocontamination, de maintenance dynamique des zones propres et d’installation aseptique des équipements de process n’ont pas été entièrement modélisées dans les environnements de simulation d’apprentissage par renforcement ; deuxièmement, l’absence d’un cadre de sélection d’algorithmes pour la vérification de la conformité aux BPF et la garantie de la continuité de la production de médicaments rend difficile l’application des algorithmes courants, tels que DQN et PPO, aux normes de qualité et de sécurité rigoureuses de la construction pharmaceutique ; enfin, le manque de mécanismes de traçabilité et de cadre réglementaire industriel pour la prise de décision par apprentissage par renforcement dans le débogage des systèmes de process pharmaceutiques et la construction de zones critiques entrave sérieusement sa mise en œuvre dans des contextes sensibles, tels que les zones critiques aseptiques.
Références
- [1]D’après le Quotidien du Peuple, depuis le début du 14e plan quinquennal, l’industrie pharmaceutique a réalisé des progrès remarquables en matière de développement qualitatif, avec un chiffre d’affaires principal en croissance à un taux annuel moyen de 9,3 % (2023). https://www.gov.cn/yaowen/liebiao/202311/content_6915215.htm (consulté le 29 octobre 2025).Google Scholar
- [2]B.-G. Hwang , SR Thomas , CH CaldasDéveloppement de mesures de performance pour les projets de construction pharmaceutiqueRevue internationale de gestion de projet , 28 ( 2010 ) , p . 265-274 , 10.1016 /j.ijproman.2009.06.004Voir le PDFVoir l’article Voir dans Scopus Google Scholar
- [3]Administration d’État chinoise pour la réglementation du marché (CSAMR), bonnes pratiques de fabrication des produits pharmaceutiques (révisé en 2010), . (2011). https://www.gov.cn/zhengce/2021-06/29/content_5723551.htm .Google Scholar
- [4]J. ZhouRecherche sur la méthode d’évaluation des risques liés à la gestion de la construction dans les industries pharmaceutiquesJ. Commer. Biotechnol. , 27 ( 2022 ) , p. 202-213 , 10.5912 / jcb1112Voir dans Scopus Google Scholar
- [5]S. Dabirian , M. Ahmadi , S. AbbaspourAnalyse de l’impact des politiques financières sur la performance des projets de construction à l’aide de la dynamique des systèmesEng., Constr. Architect. Manage.. , 30 ( 2021 ) , pp. 1201 – 1221 , 10.1108/ecam-05-2021-0431Google Scholar
- [6]R. EdirisinghePeau numérique du chantier : technologies de capteurs intelligents pour le chantier intelligent de demainEng., Constr. Architect. Manage.. , 26 ( 2019 ) , pp. 184 – 223 , 10.1108/ecam-04-2017-0066Voir l’article Voir dans Scopus Google Scholar
- [7]M. Xu , X. Nie , H. Li , JCP Cheng , Z. MeiChantiers intelligents : une approche prometteuse pour améliorer la performance de la gestion HSE sur siteJ. Build. Eng. , 49 ( 2022 ) , Article 104007 , 10.1016/j.jobe.2022.104007Voir le PDFVoir l’article Voir dans Scopus Google Scholar
- [8]V. Mnih , K. Kavukcuoglu , D. Silver , AA Rusu , J. Veness , MG Bellemare , A. Graves , M. Riedmiller , AK Fidjeland , G. Ostrovski , S. Petersen , C. Beattie , A. Sadik , I. Antonoglou , H. King , D. Kumaran , D. Wierstra , S. Legg , D. HassabisContrôle de niveau humain grâce à l’apprentissage par renforcement profondNature , 518 ( 2015 ) , p. 529-533 , 10.1038 / nature14236Voir dans Scopus Google Scholar
- [9]LP Kaelbling , ML Littman , AW MooreApprentissage par renforcement : une étudeJ.Artif. Intell. Rés. , 4 ( 1996 ) , pp. 237 – 285 , 10.1613/jair.301Voir dans Scopus Google Scholar
- [10]Y. Han, K. Sun, Z. Zhao, GQ Huang, Planification de l’aménagement modulaire d’hôpitaux hors distribution via l’apprentissage par renforcement profond augmenté de mémoire*, dans : 21e Conférence internationale IEEE sur la science et l’ingénierie de l’automatisation (CASE), IEEE, 2025 : pp. 1292–1297. 10.1109/case58245.2025.11164092 .Google Scholar
- [11]JI Guerrero , G. Miró-Amarante , A. MartínSystème d’aide à la décision pour la conception de bâtiments de soins de santé basé sur le raisonnement à partir de cas et l’apprentissage par renforcementExpert. Système. Appl. , 187 ( 2022 ) , Article 116037 , 10.1016/j.eswa.2021.116037Voir le PDFVoir l’article Voir dans Scopus Google Scholar
- [12]K. Matsumoto, A. Yamaguchi, T. Oka, M. Yasumoto, S. Hara, M. Lida, M. Teichmann, Approche d’apprentissage par renforcement basée sur la simulation pour l’automatisation des machines de construction, dans : ISARC. Actes du Symposium international sur l’automatisation et la robotique dans la construction, Publications IAARC, Waterloo, 2020 : pp. 457–464.Google Scholar
- [13]K. Mason , S. GrijalvaUne revue de l’apprentissage par renforcement pour la gestion autonome de l’énergie des bâtimentsIngénierie électronique informatique , 78 ( 2019 ) , p. 300-312 , 10.1016 / j.compeleceng.2019.07.019Voir le PDFVoir l’article Voir dans Scopus Google Scholar
- [14]L. Yu , S. Qin , M. Zhang , C. Shen , T. Jiang , X. GuanUne revue de l’apprentissage par renforcement profond pour la gestion de l’énergie des bâtiments intelligentsIEEE Internet Things Journal , 8 ( 2021 ) , p. 12046-12063 , 10.1109 / JIOT.2021.3078462Voir dans Scopus Google Scholar
- [15]H. Yu , VWY Tam , X. XuUne revue systématique de l’application de l’apprentissage par renforcement à la simulation du comportement des occupants en lien avec la consommation énergétique des bâtimentsEnergy Build. , 312 ( 2024 ) , Article 114189 , 10.1016/j.enbuild.2024.114189Voir le PDFVoir l’article Voir dans Scopus Google Scholar
- [16]V. Asghari , Y. Wang , AJ Biglari , S.-C. Hsu , P. TangL’apprentissage par renforcement en génie et gestion de la construction : une revueJ. Constr. Eng. Manage , 148 ( 2022 ) , Article 03122009 , 10.1061/(asce)co.1943-7862.0002386Voir dans Scopus Google Scholar
- [17]R. Sarkis-Onofre , F. Catalá-López , E. Aromataris , C. LockwoodComment utiliser correctement la déclaration PRISMASyst. Rev. , 10 ( 2021 ) , p. 117 , 10.1186/s13643-021-01671-zVoir dans Scopus Google Scholar
- [18]D. Moher , A. Liberati , J. Tetzlaff , DG AltmanÉléments de rapport privilégiés pour les revues systématiques et les méta-analyses : la déclaration PRISMAInt. J. Surg. , 8 ( 2009 ) , p. 336-341 , 10.1016 / j.ijsu.2010.02.007Google Scholar
- [19]QJ Wen , ZJ Ren , H. Lu , JF WuProgrès et tendances de la recherche sur le BIM : une analyse de visualisation basée sur la bibliométrieAutom. Constr. , 124 ( 2021 ) , Article 103558 , 10.1016/j.autcon.2021.103558Voir le PDFVoir l’article Voir dans Scopus Google Scholar
- [20]D. Wang , Y. Huangfu , Z. Dong , Y. DongPoints chauds de la recherche et tendances d’évolution de la neutralité carbone — Analyse visuelle des données bibliométriques basée sur CiteSpaceDurabilité. , 14 ( 2022 ) , p. 1078 , 10.3390/su14031078Google Scholar
- [21]M. Jin , J. Liu , J. Yu , Q. Zhou , W. Wu , L. Fu , C. Yin , C. Fernandez , H. Karimi-MalehÉvolution actuelle et défis futurs des techniques de détection des microplastiques : analyse et synthèse bibliométriquesSci. Prog. , 105 ( 2022 ) , Article 003685042211321 , 10.1177/00368504221132151Google Scholar
- [22]Y. Junjia , AH Alias , NA Haron , N.Abu BakarUne revue systématique bibliométrique de l’évaluation des risques de sécurité pour la construction par levage IBSBâtiments , 13 ( 2023 ) , p. 1853 , 10.3390/buildings13071853Voir dans Scopus Google Scholar
- [23]Q. Xiaoxiang , Y. Junjia , NA Haron , AH Alias , TH Law , N. Abu BakarÉtat des lieux, défis et perspectives d’avenir de l’évaluation des rénovations de bâtiments à énergie nette zéro : une revue systématique bibliométriqueEnergies. (Bâle) , 17 ( 2024 ) , p. 3826 , 10.3390/en17153826Voir dans Scopus Google Scholar
- [24]Y. Junjia , AH Alias , NA Haron , N.Abu BakarApprentissage profond pour la gestion des risques liés à la sécurité dans la construction modulaire : état des lieux, atouts, défis et perspectives d’avenirAutom. Constr. , 169 ( 2025 ) , Article 105894 , 10.1016/j.autcon.2024.105894Voir le PDFVoir l’article Voir dans Scopus Google Scholar
- [25]JW Drisko , T. MaschiAnalyse de contenuOxford University Press , New York ( 2016 )Google Scholar
- [26]S. Golazad , A. Mohammadi , A. Rashidi , M. IlbeigiDu brut au raffiné : prétraitement des données pour les modèles d’apprentissage automatique (ML), d’apprentissage profond (DL) et d’apprentissage par renforcement (RL) dans le secteur de la constructionAutom. Constr. , 168 ( 2024 ) , Article 105844 , 10.1016/j.autcon.2024.105844Voir le PDFVoir l’article Voir dans Scopus Google Scholar
- [27]B. Singh , R. Kumar , V.P. SinghApprentissage par renforcement dans les applications robotiques : une étude exhaustiveArtif. Intell. Rév. , 55 ( 2021 ) , pp. 945 – 990 , 10.1007/s10462-021-09997-9Google Scholar
- [28]X. Lei , Y. Dong , DM FrangopolÉlaboration de politiques de maintenance durable du cycle de vie pour les ponts en dégradation au niveau du réseau à l’aide d’un auto-encodeur convolutif – agent d’apprentissage par renforcement structuréJ. Bridge Ing. , 28 ( 2023 ) , Article 04023063 , 10.1061/jbenf2.beeng-6159Voir dans Scopus Google Scholar
- [29]A. Déria , P. Ghannad , Y.-C. LeeOptimisation dynamique en temps réel de l’affectation d’unités modulaires à des installations hors site dans le cadre de la reconstruction post-catastrophe grâce à l’apprentissage par renforcement profondJ. Gérer. Ing. , 40 ( 2024 ) , article 04024021 , 10.1061/jmenea.meeng-5900Voir dans Scopus Google Scholar
- [30]GM Ali , A. Bouferguene , M. Al-HusseinOptimisation de la disposition des tapis de grue basée sur une approche gloutonne et d’apprentissage par renforcement à base d’agentsJ. Constr. Eng. Manage , 149 ( 2023 ) , Article 04023067 , 10.1061/jcemd4.coeng-12891Voir dans Scopus Google Scholar
- [31]M. Cheng , DM FrangopolUn cadre décisionnel pour la planification de la capacité portante des ponts vieillissants utilisant l’apprentissage par renforcement profondJ. Comput. Civil Eng. , 35 ( 2021 ) , Article 04021024 , 10.1061/(asce)cp.1943-5487.0000991Voir dans Scopus Google Scholar
- [32]J. Cai , A. Du , X. Liang , S. LiPlanification de trajectoires basée sur la prédiction pour une collaboration homme-robot sûre et efficace dans le secteur de la construction grâce à l’apprentissage par renforcement profondJ. Comput. Civil Eng. , 37 ( 2023 ) , Article 04022046 , 10.1061/(asce)cp.1943-5487.0001056Voir dans Scopus Google Scholar
- [33]DY YangGestion adaptative du cycle de vie des structures à grande échelle basée sur les risques, utilisant l’apprentissage par renforcement profond et la modélisation par approximation.J. Ing. Mécanique. , 148 ( 2022 ) , Article 04021126 , 10.1061/(asce)em.1943-7889.0002028Voir dans Scopus Google Scholar
- [34]SJ Hormozabad , N. Jacobs , MG SotoApprentissage par renforcement pour le contrôle structurel intégré et la surveillance de l’état de santéPract. Period. Struct. Design Constr. , 29 ( 2024 ) , Article 04024026 , 10.1061/ppscfx.sceng-1455Voir dans Scopus Google Scholar
- [35]M. ElMenshawy , L. Wu , B. Gue , S. AbouRizkAutomatisation de la planification de la fabrication des tronçons de tuyauterie pour les projets de construction industrielle modulaire grâce à l’apprentissage par renforcementJ. Comput. Civil Eng. , 39 ( 2025 ) , Article 04025013 , 10.1061/jccee5.cpeng-6042Voir dans Scopus Google Scholar
- [36]W. SerranoAlgorithmes d’apprentissage par renforcement profond dans les infrastructures intelligentesInfrastructures. (Bâle) , 4 ( 2019 ) , p. 52 , 10.3390/infrastructures4030052Voir dans Scopus Google Scholar
- [37]C. Zhang , X. Zhou , C. Xu , Z. Wu , J. Liu , H. QiGénération automatique de plans de fabrication d’éléments préfabriqués en béton à partir de données BIM et d’un apprentissage par renforcement multi-agentsBâtiments , 15 ( 2025 ) , p. 284 , 10.3390/buildings15020284Google Scholar
- [38]M. Kim , Y. Ham , C. Koo , T.W. KimSimulation des déplacements des ouvriers sur un chantier de construction par apprentissage par renforcement profond, en tenant compte de leur cognition spatiale et de leur comportement d’orientation.Autom. Constr. , 147 ( 2023 ) , Article 104715 , 10.1016/j.autcon.2022.104715Voir le PDFVoir l’article Voir dans Scopus Google Scholar
- [39]P. Lin , L. Zhang , RLK Tiong , X. SongApprentissage par renforcement profond guidé par la physique pour un fonctionnement amélioré des tunneliers prenant en compte la stabilité de l’inertie cinétiqueAdv. Eng. Inform. , 63 ( 2025 ) , Article 102943 , 10.1016/j.aei.2024.102943Voir le PDFVoir l’article Voir dans Scopus Google Scholar
- [40]P. Lin , A. Ji , Y. Zhou , L. Zhang , RLK TiongCommande automatisée de la position d’un tunnelier pendant l’excavation à l’aide d’un apprentissage par renforcement profond prenant en compte la dynamique spatio-temporelleAppl. Soft. Comput. , 167 ( 2024 ) , Article 112234 , 10.1016/j.asoc.2024.112234Voir le PDFVoir l’article Voir dans Scopus Google Scholar
- [41]KM Alhamed , C. Iwendi , AK Dutta , B. Almutairi , H. Alsaghier , S. AlmotairiConstruction de bâtiments basée sur la vidéosurveillance et l’apprentissage par renforcement profond utilisant un réseau électrique intelligentComput. Electric. Eng. , 103 ( 2022 ) , Article 108273 , 10.1016/j.compeleceng.2022.108273Voir le PDFVoir l’article Voir dans Scopus Google Scholar
- [42]M. Amani , R. AkhavianOptimisation ergonomique intelligente dans l’interaction bimanuelle opérateur-robot : une approche d’apprentissage par renforcementAutom. Constr. , 168 ( 2024 ) , Article 105741 , 10.1016/j.autcon.2024.105741Voir le PDFVoir l’article Voir dans Scopus Google Scholar
- [43]D. Lee , S. Lee , N. Masoud , MS Krishnan , VC LiApprentissage par renforcement profond piloté par jumeau numérique pour l’allocation adaptative des tâches dans la construction robotiqueAdv. Eng. Inform. , 53 ( 2022 ) , Article 101710 , 10.1016/j.aei.2022.101710Voir le PDFVoir l’article Voir dans Scopus Google Scholar
- [44]P. Lin , M. Wu , Z. Xiao , RLK Tiong , L. ZhangApprentissage par renforcement profond basé sur la physique pour améliorer la vitesse d’avancement et la stabilité des tunneliersAutom. Constr. , 158 ( 2023 ) , Article 105234 , 10.1016/j.autcon.2023.105234Google Scholar
- [45]RK Soman , M. Molina-SolanaAutomatisation de la génération de plannings prévisionnels pour la construction grâce à la vérification des contraintes basée sur les données liées et l’apprentissage par renforcementAutom. Constr. , 134 ( 2022 ) , Article 104069 , 10.1016/j.autcon.2021.104069Voir le PDFVoir l’article Voir dans Scopus Google Scholar
- [46]Y. Cao , W. Luo , Y. Xue , W. Lin , F. ZhangCadre d’apprentissage par renforcement hors ligne basé sur un modèle pour l’optimisation du fonctionnement des tunneliersEspace souterrain , 19 ( 2024 ) , p. 47-71 , 10.1016 / j.undsp.2024.01.008Voir le PDFVoir l’article Voir dans Scopus Google Scholar
- [47]D. Lee , M. KimSystème de levage de chantier autonome basé sur l’apprentissage par renforcement profond pour la construction d’immeubles de grande hauteurAutom. Constr. , 128 ( 2021 ) , Article 103737 , 10.1016/j.autcon.2021.103737Voir le PDFVoir l’article Voir dans Scopus Google Scholar
- [48]X. Liu , W. Zhang , C. Shao , Y. Wang , Q. CongCommande intelligente autonome d’un tunnelier à pression de terre équilibrée basée sur l’apprentissage par renforcement profondIng. Appl. Artif. Intell. , 125 ( 2023 ) , Article 106702 , 10.1016/j.engappai.2023.106702Voir le PDFVoir l’article Voir dans Scopus Google Scholar
- [49]Z. Zhang , Z. Guo , H. Zheng , Z. Li , PF YuanComposition spatiale architecturale automatisée via l’apprentissage par renforcement profond multi-agents pour la rénovation de bâtimentsAutom. Constr. , 167 ( 2024 ) , Article 105702 , 10.1016/j.autcon.2024.105702Voir le PDFVoir l’article Voir dans Scopus Google Scholar
- [50]Y. Pan , Y. Shen , J. Qin , L. ZhangApprentissage par renforcement profond pour l’optimisation multi-objectif dans la conception de bâtiments écologiques basée sur le BIMAutom. Constr. , 166 ( 2024 ) , Article 105598 , 10.1016/j.autcon.2024.105598Voir le PDFVoir l’article Voir dans Scopus Google Scholar
- [51]CH Lin , B. Fu , L. Zhang , N. Li , GS TongConception intelligente de poutres composites acier-béton basée sur l’apprentissage par renforcement profondStructures , 70 ( 2024 ) , Article 107666 , 10.1016/j.istruc.2024.107666Voir le PDFVoir l’article Voir dans Scopus Google Scholar
- [52]X. Tang , B. Yi , Z. Wang , MT Quasim , S. Basheer , B. LiangOptimisation multi-objectif basée sur l’apprentissage par renforcement profond pour les bâtiments de soins de santé intelligents en carbone et compatibles avec l’IIoTIEEE Internet Things Journal , 12 ( 2025 ) , p. 34768-34779 , 10.1109 / jiot.2025.3579055Voir dans Scopus Google Scholar
- [53]TF Hansen , GH Erharter , T. MarcherVers une politique de changement de fraise TBM pilotée par l’apprentissage par renforcementAutom. Constr. , 165 ( 2024 ) , Article 105505 , 10.1016/j.autcon.2024.105505Voir le PDFVoir l’article Voir dans Scopus Google Scholar
- [54]Y. Liu , Y. Wang , Z. ZhouSimulation d’opérations cohérentes d’excavatrices lors de travaux de terrassement basée sur l’apprentissage par renforcementBâtiments , 14 ( 2024 ) , p. 3270 , 10.3390/buildings14103270Voir dans Scopus Google Scholar
- [55]Q. Fu , K. Li , J. Chen , J. Wang , Y. Lu , Y. WangPrédiction de la consommation énergétique des bâtiments à l’aide d’une méthode DQN basée sur les forêts profondesBâtiments , 12 ( 2022 ) , p. 131 , 10.3390/buildings12020131Voir dans Scopus Google Scholar
- [56]Y. Yao , VWY Tam , J. Wang , KN Le , A. ButeraPlanification automatisée de la construction utilisant l’apprentissage par renforcement profond avec échantillonnage d’actions validesAutom. Constr. , 166 ( 2024 ) , Article 105622 , 10.1016/j.autcon.2024.105622Voir le PDFVoir l’article Voir dans Scopus Google Scholar
- [57]O. Azulay , A. ShapiroContrôleur de godet de chargeuse sur pneus utilisant l’apprentissage par renforcement profondIEEE Access , 9 ( 2021 ) , p. 24145-24154 , 10.1109 / access.2021.3056625Voir dans Scopus Google Scholar
- [58]I. Kurinov , G. Orzechowski , P. Hämäläinen , A. MikkolaExcavatrice automatisée basée sur l’apprentissage par renforcement et la dynamique des systèmes multicorpsIEEE Access , 8 ( 2020 ) , p. 213998-214006 , 10.1109 / ACCESS.2020.3040246Voir dans Scopus Google Scholar
- [59]A. Ibrahim , W. Torres-Calderon , M. Golparvar-FardApprentissage par renforcement pour la cartographie de la réalité de haute qualité des constructions intérieures à l’aide de véhicules terrestres sans piloteAutom. Constr. , 156 ( 2023 ) , Article 105110 , 10.1016/j.autcon.2023.105110Voir le PDFVoir l’article Voir dans Scopus Google Scholar
- [60]T. Osa , M. AizawaApprentissage par renforcement profond avec entraînement antagoniste pour l’excavation automatisée à l’aide d’images de profondeurIEEE Access , 10 ( 2022 ) , p. 4523-4535 , 10.1109 / access.2022.3140781Voir dans Scopus Google Scholar
- [61]AA Apolinarska , M. Pacher , H. Li , N. Côté , R. Pastrana , F. Gramazio , M. KohlerAssemblage robotisé de joints de bois par apprentissage par renforcementAutom. Constr. , 125 ( 2021 ) , Article 103569 , 10.1016/j.autcon.2021.103569Voir le PDFVoir l’article Voir dans Scopus Google Scholar
- [62]C. Jiang , X. Li , J.-R. Lin , M. Liu , Z. MaContrôle adaptatif des flux de ressources pour optimiser les travaux de construction et les flux de trésorerie grâce à l’apprentissage par renforcement profond en ligneAutom. Constr. , 150 ( 2023 ) , Article 104817 , 10.1016/j.autcon.2023.104817Voir le PDFVoir l’article Voir dans Scopus Google Scholar
- [63]AY Yasutomi , H. Ichiwara , H. Ito , H. Mori , T. OgataAttention visuo-spatiale et apprentissage par renforcement basé sur les données proprioceptives pour une tâche robuste d’insertion de cheville dans un trou dans des conditions variablesRobot IEEE. Automatique. Lett. , 8 ( 2023 ) , pp. 1834 – 1841 , 10.1109/lra.2023.3243526Voir dans Scopus Google Scholar
- [64]A. Zhu , T. Dai , G. Xu , P. Pauwels , BD Vries , M. FangApprentissage par renforcement profond pour la planification d’assemblage en temps réel dans la construction préfabriquée robotiséeIEEE Trans. Autom. Sci. Eng. , 20 ( 2023 ) , p. 1515-1526 , 10.1109 /tase.2023.3236805Voir dans Scopus Google Scholar
- [65]J. Liu , P. Liu , L. Feng , W. Wu , D. Li , YF ChenRésolution automatisée des conflits pour la conception des armatures en acier dans les ossatures en béton via l’apprentissage par renforcement Q-learning et la modélisation des informations du bâtimentAutom. Constr. , 112 ( 2020 ) , Article 103062 , 10.1016/j.autcon.2019.103062Voir le PDFVoir l’article Voir dans Scopus Google Scholar
- [66]W. Chen , Z. Zhang , D. Tang , C. Liu , Y. Gui , Q. Nie , Z. ZhaoÉvaluation d’un algorithme d’apprentissage par renforcement basé sur LSTM-PPO pour résoudre le problème d’ordonnancement dynamique d’atelierIngénierie industrielle et informatique , 197 ( 2024 ) , Article 110633 , 10.1016/j.cie.2024.110633Voir le PDFVoir l’article Voir dans Scopus Google Scholar
- [67]MO Ahmed , IH El-adawayModélisation intégrée par théorie des jeux et apprentissage par renforcement pour les appels d’offres en plusieurs étapes dans le secteur de la construction et des infrastructuresConstr. Manage. Econ. , 41 ( 2022 ) , p. 1-25 , 10.1080 / 01446193.2022.2124528Google Scholar
- [68]HS Fard , H. Parvin , M. MahmoudiAmélioration des prédictions de l’effet de rétrécissement dans les tunnels rocheux grâce à l’apprentissage Q d’ensemble et aux chaînes de Markov en ligneSci. Rep. , 14 ( 2024 ) , Article 22885 , 10.1038/s41598-024-72998-5Voir dans Scopus Google Scholar
- [69]F. Peng , H. Liu , L. ZhengUne méthode d’apprentissage par renforcement hybride Sarsa pour la prévision de la puissance des batteries robotiquesJ. Cent. South. Univ. , 30 ( 2023 ) , pp. 3867 – 3880 , 10.1007/s11771-023-5451-0Voir dans Scopus Google Scholar
- [70]C. Yu , G. Yan , K. Ruan , X. Liu , C. Yu , X. MiUn réseau de portes d’apprentissage par renforcement convolutionnel ensembliste pour la prévision des PM2.5 dans les stations de métroÉvaluation des risques liés à la recherche stochastique et environnementale ( 2023 ) , 10.1007/s00477-023-02564-4Google Scholar
- [71]R. Li , Z. ZouAmélioration de l’apprentissage des robots de construction pour les tâches collaboratives et à long terme grâce à l’apprentissage par imitation générative adverseAdv. Eng. Inform. , 58 ( 2023 ) , Article 102140 , 10.1016/j.aei.2023.102140Voir le PDFVoir l’article Voir dans Scopus Google Scholar
- [72]G. Zhu , Z. Shen , L. Liu , S. Zhao , F. Ji , Z. Ju , J. SunMéthode d’évitement d’obstacles dynamique pour AUV basée sur un algorithme PPO amélioréIEEE Access , 10 ( 2022 ) , p. 121340-121351 , 10.1109 / access.2022.3223382Voir dans Scopus Google Scholar
- [73]D. Yao , G. de S. BorjaAmélioration de l’identification des cyber-risques dans le secteur de la construction grâce aux modèles de langageAutom. Constr. , 165 ( 2024 ) , Article 105565 , 10.1016/j.autcon.2024.105565Voir le PDFVoir l’article Voir dans Scopus Google Scholar
- [74]CJ Liang , VR Kamat , CC MenassaApprendre aux robots à effectuer des tâches de construction quasi répétitives par le biais de démonstrations humainesAutom. Constr. , 120 ( 2020 ) , Article 103370 , 10.1016/j.autcon.2020.103370Voir le PDFVoir l’article Voir dans Scopus Google Scholar
- [75]W. Cai , L. Huang , Z. ZouUne approche intégrée combinant environnements virtuels et apprentissage par renforcement pour former des robots de construction à réaliser des tâches en situation d’incertitude.Notes de cours en génie civil , 363 ( 2023 ) , p. 259-271 , 10.1007 /978-3-031-34593-7_17Voir dans Scopus Google Scholar
- [76]J. Feng , Z. Ren , W. LiDispatching basé sur les risques des réseaux électriques intégrant la corrélation spatio-temporelle et reposant sur un algorithme robuste de type acteur-critique soupleIEEE Trans. Power Syst. ( 2024 ) , pp. 1 – 14 , 10.1109/tpwrs.2024.3496936Voir dans Scopus Google Scholar
