




Apprentissage par renforcement profond pour l’optimisation de l’irrigation : avantages, opportunités et défis
- Examinez l’application de l’apprentissage par renforcement profond (DRL) à l’irrigation agricole.
- Analyser les performances des algorithmes DRL dans la prise de décision en matière d’irrigation.
- Comparer les modèles DRL basés sur différents environnements dans l’optimisation de l’irrigation.
- Discuter des travaux supplémentaires à mener pour améliorer les performances du DRL dans l’optimisation de l’irrigation.
Points forts
Résume
L’apprentissage par renforcement (RL) est performant dans un environnement changeant, mais conduit facilement à des solutions sous-optimales avec des données de grande dimension. L’apprentissage par renforcement profond (DRL), qui fusionne le RL et l’apprentissage profond (DL), excelle dans l’apprentissage de stratégies d’irrigation adaptatives et à long terme directement à partir de données environnementales de grande dimension. Cet article passe en revue les applications du DRL à l’optimisation de l’irrigation, en considérant à la fois les environnements pré-entraînés basés sur des simulateurs de croissance des cultures et les environnements dynamiques pilotés par des capteurs en temps réel. Nous avons examiné les atouts des algorithmes DRL classiques, notamment leur capacité à gérer des environnements dynamiques et non linéaires, et analysé leurs performances en matière d’optimisation multi-objectifs et de prise de décision pour l’irrigation. De plus, nous avons identifié les contraintes liées à l’application du DRL à la prise de décision en irrigation, telles que la rareté des données, la faible interprétabilité des modèles et les difficultés de déploiement sur le terrain. Il apparaît que le DRL peut constituer un cadre puissant pour l’irrigation adaptative, mais qu’il est limité par l’écart entre la complexité de la simulation et celle du monde réel. Pour pallier ces limitations, nous avons évoqué des pistes de recherche futures, comme le développement d’algorithmes d’apprentissage par renforcement profond multi-objectifs. Ces approches permettront d’améliorer les résultats de la modélisation par renforcement profond et de fournir un socle technologique pour une agriculture intelligente et une gestion durable des ressources.
1. Introduction
L’agriculture, enjeu majeur à l’échelle mondiale, est confrontée au défi du développement durable (
Konefal et al., 2023 ). Pour y répondre, le concept d’agriculture intelligente a été introduit, intégrant des technologies de l’information avancées telles que l’Internet des objets (IdO) (
Quy et al., 2022 ), l’intelligence artificielle (IA) (
Sharma et al., 2022 ), l’analyse des mégadonnées (
Bhat et Huang, 2021 ) et le cloud computing (
Zamora-Izquierdo et al., 2019 ;
Kalyani et Collier, 2021 ). Ces technologies permettent une gestion intelligente, précise et automatisée de la production agricole (
Shaikh et al., 2022 ). L’un des principaux défis de l’agriculture réside dans l’utilisation rationnelle des ressources en eau (
Pimentel et al., 2004 ). Dans ce contexte, le concept d’irrigation intelligente (
Bwambale et al., 2022 ) a été proposé, intégrant les principes de l’agriculture intelligente à une utilisation efficiente des ressources en eau.En général, les méthodes d’irrigation reposent sur l’expérience ou sur une simple programmation horaire : les méthodes statiques assurent un apport d’eau de base aux cultures, mais sont insensibles aux variables environnementales (
Elliott et al., 2014 ) ; les programmes d’irrigation fixes ne peuvent être ajustés en fonction des besoins en eau des cultures et des conditions météorologiques en temps réel (
Hassanli et al., 2009 ). L’irrigation intelligente intègre la gestion de l’irrigation aux technologies de l’information pour surveiller et réagir automatiquement aux variations d’humidité du sol (
Liao et al., 2021 ), aux conditions climatiques (
Li et al., 2024 ) et aux besoins des cultures (
Wu et al., 2017 ), dans le but d’améliorer la productivité et la durabilité agricoles. Grâce à l’Internet des objets (IoT), des données de terrain en temps réel sont disponibles pour la gestion de l’irrigation. Il est ainsi possible de suivre les différentes phases de croissance du cycle de vie d’une culture et de proposer des traitements d’irrigation dynamiques (
Roy et al., 2021 ). Cependant, il est difficile de créer des plans d’irrigation personnalisés, de prévoir les événements météorologiques extrêmes et d’ajuster les stratégies d’irrigation en utilisant uniquement l’Internet des objets (IoT) (
Villa-Henriksen et al., 2020 ). Les algorithmes d’apprentissage automatique sont couramment utilisés pour la reconnaissance de formes et la prédiction à partir de données historiques (
Goldstein et al., 2018 ) et donnent de bons résultats pour la prédiction du stress hydrique des cultures (
Virnodkar et al., 2020 ), de l’humidité du sol (
Togneri et al., 2022 ) et de l’évapotranspiration (ET0) (
Zhu et al., 2020 ). Ces algorithmes sont généralement performants avec des ensembles de données statiques ou peu variables et ne permettent pas une prise de décision en temps réel.
Goap et al. (2018) ont développé un modèle de régression à vecteurs de support (SVR) combiné à un algorithme de clustering k-means basé sur les technologies IoT pour prédire les tendances de l’humidité du sol. La gestion de l’irrigation a été mise en œuvre en fonction de l’évolution des tendances, mais sa précision est très sensible au bruit et aux données manquantes. De plus, les modèles d’apprentissage profond ne permettent généralement pas d’ajuster dynamiquement les stratégies d’irrigation et manquent de capacités d’optimisation en temps réel (
Umutoni et Samadi, 2024 ).Les algorithmes d’apprentissage par renforcement (AR) apprennent des stratégies optimales en interagissant directement avec l’environnement et s’adaptent dynamiquement aux changements pour prendre des décisions en temps réel (
François-Lavet et al., 2018 ). En gestion de l’irrigation, les algorithmes AR sont généralement utilisés pour élaborer des stratégies d’irrigation à partir de données en temps réel (humidité du sol, conditions météorologiques, stades de croissance des cultures, etc.) afin d’optimiser l’efficience de l’utilisation de l’eau et le rendement des cultures (
Chen et al., 2021 ). Une fonction de récompense est définie pour quantifier l’efficacité des décisions d’irrigation. L’objectif principal des algorithmes AR est d’obtenir la récompense cumulée maximale grâce à un processus itératif qui détermine l’action à entreprendre dans chaque état. Ce processus implique généralement un équilibre entre exploration (test de nouvelles stratégies d’irrigation, par exemple) et exploitation (utilisation des meilleures stratégies connues, par exemple) (
Ladosz et al., 2022 ). L’apprentissage par renforcement profond (DRL) a démontré sa polyvalence et son potentiel dans des applications telles que les systèmes de conduite autonome (
Kiran et al., 2022 ), la robotique (
Li et al., 2020 ), la finance (
Deng et al., 2017 ) et la santé (
Zhou et al., 2021 ), en combinant les capacités de traitement de données multidimensionnelles de l’apprentissage profond avec les stratégies d’optimisation de la prise de décision de l’apprentissage par renforcement. En agriculture, le DRL se distingue des autres modèles d’apprentissage automatique par son approche qui met l’accent à la fois sur la prédiction et l’ajustement intelligent en temps réel de l’environnement agricole (
Bu et Wang, 2019 ). Le DRL excelle dans la résolution de problèmes d’optimisation multivariables grâce à son apprentissage par essais et erreurs inhérent et à son mécanisme de rétroaction en boucle fermée, notamment l’intégration de données provenant de diverses sources (
Zhu et al., 2023 ) et l’adaptation rapide à de nouvelles tâches (
Chen et al. (2025)Nous avons développé un système en boucle fermée utilisant un algorithme d’apprentissage par renforcement acteur-critique distributionnel pour améliorer l’irrigation du coton en combinant des données environnementales en temps réel avec une simulation de la dynamique de croissance des cultures. Cette approche s’avère efficace même en conditions météorologiques incertaines, permettant d’accroître le rendement du coton de 13,6 % et de réduire la consommation d’eau de 6,7 %. Les simulations simples échouent dans la prise de décision en matière d’irrigation en conditions réelles. Des facteurs clés, comme la biologie des cultures, sont souvent négligés, ce qui entraîne une faible fidélité environnementale et un écart entre la simulation et la réalité. De plus, l’apprentissage par renforcement profond (DRL) peine à planifier les changements lents, tels que la croissance des cultures ou l’humidité du sol, en raison d’une observabilité partielle et d’une dynamique non markovienne. Il est difficile de concevoir une récompense unique pour optimiser simultanément plusieurs objectifs, comme l’augmentation du rendement et de l’efficience de l’utilisation de l’eau. Les actions améliorant l’efficience immédiate de l’eau peuvent impacter négativement une récompense ultérieure (par exemple, le rendement final). Il est donc nécessaire de définir une fonction de récompense équilibrée afin d’éviter de privilégier les gains à court terme au détriment des objectifs à long terme.Cet article se concentre principalement sur l’application de l’apprentissage par renforcement profond (DRL) à la planification de l’irrigation et à la prise de décision intelligente. Nous y abordons l’applicabilité de différentes méthodes DRL à la gestion de l’irrigation, comparons leurs forces et leurs faiblesses, et présentons nos perspectives de recherche. La structure de cet article est la suivante :
la section 2 offre une vue d’ensemble du DRL et de ses principaux algorithmes pour la planification de l’irrigation.
La section 3 présente quelques applications classiques du DRL à l’optimisation de l’irrigation.
La section 4 examine les limitations actuelles et les solutions potentielles liées à l’utilisation des modèles d’apprentissage par renforcement. Enfin,
la section 5 conclut cet article et présente nos travaux futurs dans ce domaine.
2. Contexte
2.1 . Apprentissage par renforcement profond
L’apprentissage par renforcement (RL) repose sur l’apprentissage par essais et erreurs, les récompenses obtenues servant de base à l’amélioration comportementale (
Holroyd et Coles, 2002 ). Il diffère du modèle algorithmique de traitement de données traditionnel, qui comprend la sélection, l’entraînement et le test. Le RL s’appuie plutôt sur le processus de décision markovien (MDP) pour résoudre les problèmes de prise de décision séquentielle (
Sutton et al., 1999 ). En définissant l’espace d’états (S), l’espace d’actions (A), les probabilités de transition (P), la fonction de récompense (R) et le facteur d’actualisation (γ), les MDP permettent aux agents de prendre des décisions dans des environnements incertains afin de maximiser les récompenses cumulées (
Puterman, 1994 ). Généralement, dans les environnements stochastiques, le RL se divise en méthodes sans modèle et méthodes avec modèle. Le modèle fait référence à la dynamique de l’environnement interagissant avec l’agent (c’est-à-dire le MDP). Les algorithmes de RL avec modèle sont utilisés lorsque les éléments du modèle sont connus (
Moerland et al., 2022 ). Dans des scénarios d’environnement complexe sans paramètres de modèle précis, des méthodes RL sans modèle sont nécessaires pour apprendre directement à partir des interactions avec l’environnement afin de trouver la stratégie optimale (
Bellemare et al., 2017 ).En apprentissage par renforcement (RL), la programmation dynamique (DP) (
Bellman, 1966 ), les méthodes de Monte Carlo (MC) (
Browne et al., 2012 ) et l’apprentissage par différence temporelle (TD) (
Sutton, 1988 ) reposent toutes sur le cadre des processus de décision markoviens (MDP) pour trouver la politique optimale. Comme le montre le
tableau 1 , le RL trouve son origine dans deux champs de recherche : l’approche d’apprentissage basée sur un modèle pour le contrôle optimal (
Bertsekas, 2019 ) et l’approche d’apprentissage sans modèle pour l’apprentissage par essais et erreurs (
Kaelbling et al., 1996 ). La DP est un algorithme courant pour le contrôle optimal, qui introduit des fonctions de valeur pour optimiser la trajectoire des actions (variables de contrôle) en résolvant l’équation de Bellman (
Bellman et Dreyfus, 2015 ). Les algorithmes d’apprentissage par essais et erreurs sont centrés sur la méthode MC pour améliorer la politique en évaluant de manière itérative ses performances dans l’environnement (
Osorio-Lird et al., 2018 ). S’appuyant sur les concepts de programmation dynamique (DP) et de modélisme multicritère (MC), avec la théorie des dimensions (TD) comme élément central, cette approche met l’accent sur l’apprentissage à partir de données empiriques ainsi que sur le stockage des solutions aux sous-problèmes pour le calcul récursif. Ceci a conduit à la proposition d’algorithmes d’apprentissage par table Q intégrant la DP et le MC (
Watkins et Dayan, 1992 ). Cette approche est adaptée aux scénarios avec un espace d’états fini permettant un accès/une modification sous forme de table ou de vecteur à tout moment. Les méthodes d’apprentissage par renforcement (RL) présentent des limitations pour les espaces d’états continus et les problèmes de décision complexes en raison du fléau de la dimensionnalité (
Williams, 1992 ). Les fondements de l’apprentissage par renforcement profond (DRL ) (
Fig. 1 (c)) reposent sur l’apprentissage par renforcement (RL) (
Fig. 1 (a)), un sous-domaine de l’apprentissage automatique (ML) où un agent apprend à prendre des décisions séquentielles en recevant des récompenses de son environnement. L’apprentissage par renforcement (RL) est limité aux problèmes simples et peut modéliser des problèmes complexes en le combinant avec l’apprentissage profond (DL) (
Fig. 1 (b)), un autre sous-domaine de l’apprentissage automatique qui excelle dans l’extraction de caractéristiques à partir de données de grande dimension grâce aux réseaux de neurones profonds (
Henderson et al., 2018 ). Les premières avancées en apprentissage par renforcement profond (DRL) ont eu lieu dans le domaine du jeu vidéo (
Mnih et al., 2013 ), où l’équipe Google DeepMind a combiné des réseaux de neurones profonds avec l’apprentissage par renforcement Q-learning pour résoudre avec succès les problèmes de prise de décision dans les jeux vidéo (
Fig. 2 ). Ceci démontre la capacité du DRL à traiter des problèmes non linéaires complexes et à optimiser les décisions en temps réel en fonction des retours d’information de l’environnement. Les algorithmes de DRL peuvent être principalement classés en trois catégories : les méthodes basées sur la valeur, les méthodes basées sur les politiques et les méthodes acteur-critique.
Tableau 1. Le développement du DRL.
| Nom | Applications | Réf. |
|---|---|---|
| Apprentissage par renforcement (RL) | Recherche de la stratégie d’interaction optimale entre un décideur (un agent) et le système (l’environnement) dans lequel il évolue. Les actions sont améliorées en renforçant celles qui sont récompensées et en supprimant celles qui sont punies. | Dayan et Balleine, 2002 ; Skinner, 2019 ; Thorndike, 2017 |
| Programmation dynamique (PD) | Résolution du processus de décision markovien (MDP) par un mécanisme similaire à la méthode itérative par essais et erreurs de l’apprentissage par renforcement. Une solution récursive est appliquée pour trouver la politique optimale en décomposant le problème en sous-problèmes lorsque les probabilités de transition et les fonctions de récompense de l’environnement sont connues. | Puterman (1994) Lewis et al. (2012) |
| Méthodes de Monte Carlo (MC) | Il n’est pas nécessaire de connaître les probabilités de transition ni les fonctions de récompense de l’environnement. L’estimation de la fonction de valeur se fait par le biais de chemins complets (épisodes) allant de l’état initial à l’état final. | Kroese et coll. (2013) Rubinstein et Kroese (2016) Wang et al. (2024) |
| Apprentissage par différence temporelle (TD) | Combinant les atouts des méthodes DP et MC, la fonction de valeur de l’état actuel est mise à jour grâce à la récompense actuelle et à la valeur estimée de l’état suivant, sans nécessiter un épisode complet. | Sutton (1988) Tesauro et coll. (1995) Rowland (2024) |
| L’apprentissage par renforcement (Q-learning) et la table Q | Une approche basée sur la valeur avec une structure de critique unique. Elle utilise le concept de TD pour approcher la politique optimale en mettant à jour continuellement la table Q et en résolvant des problèmes de processus de décision markoviens finis. La table Q est un tableau bidimensionnel qui enregistre les rendements attendus pour différentes actions dans chaque état. | Watkins et Dayan (1992) Rummery et Niranjan (1994) Sutton et al. (1998) |
| Méthodes de gradient de politique | Méthode basée sur une politique à un seul acteur. Elle utilise l’apprentissage par essais et erreurs pour paramétrer la politique et exploite les trajectoires d’état générées par les interactions entre la politique et l’environnement. Elle estime le gradient des paramètres de la politique qui maximisent les récompenses cumulées afin d’améliorer cette dernière. | Williams (1992) Sutton et coll. (1999) Kakade (2001) |
| Acteur-critique | Cette approche combine des éléments des méthodes fondées sur les valeurs et des méthodes fondées sur les politiques. L’acteur interagit avec l’environnement, et le critique évalue et améliore la performance de l’acteur. | Konda et Tsitsiklis (1999) Lowe et al. (2017) Fujimoto et coll. (2018) |
| Réseau Q profond | Combinaison de réseaux de neurones convolutifs (CNN) et d’apprentissage par renforcement (Q-learning) pour approximer la fonction de valeur Q. Résolution des problèmes liés à deux distributions indépendantes basées sur la réutilisation de l’expérience et des réseaux cibles indépendants. | Mnih et coll. (2013) Schaul et coll. (2016) Van Hasselt et coll., (2016) |
| Apprentissage par renforcement profond (DRL) | Ce modèle s’appuie sur DQN, qui utilise des réseaux neuronaux profonds pour approximer la fonction de politique (acteur) et la fonction de valeur d’action (critique). Il calcule les probabilités de toutes les actions possibles et la valeur de chaque action dans des espaces d’actions continus, et présente divers algorithmes capables de résoudre efficacement les problèmes d’actions continues de grande dimension. | Arulkumaran et coll. (2017) François-Lavet et al. (2018) Henderson et coll. (2018) |
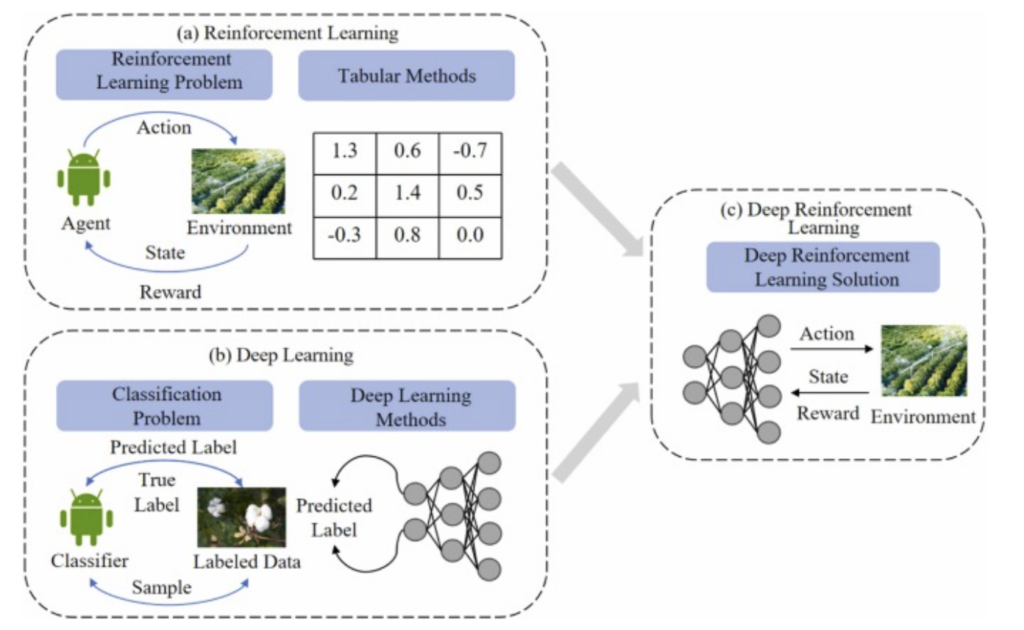
Figure 1. Cadres
de (a) l’apprentissage par renforcement, où les valeurs numériques du tableau représentent les rendements attendus (valeurs Q) pour différentes actions dans divers états, et l’agent sélectionne une action en fonction de l’état environnemental actuel et reçoit une récompense pour optimiser progressivement sa politique en mettant à jour les valeurs du tableau ; (b) l’apprentissage profond, où le classificateur reçoit des échantillons de données étiquetés, produit des étiquettes prédites, les compare aux étiquettes réelles et optimise les paramètres du réseau par rétropropagation ; et (c) l’apprentissage par renforcement profond, où l’agent traite directement les états environnementaux bruts via des réseaux neuronaux profonds pour prédire les fonctions/politiques de valeur d’action et met à jour les paramètres du réseau en fonction du signal de récompense.
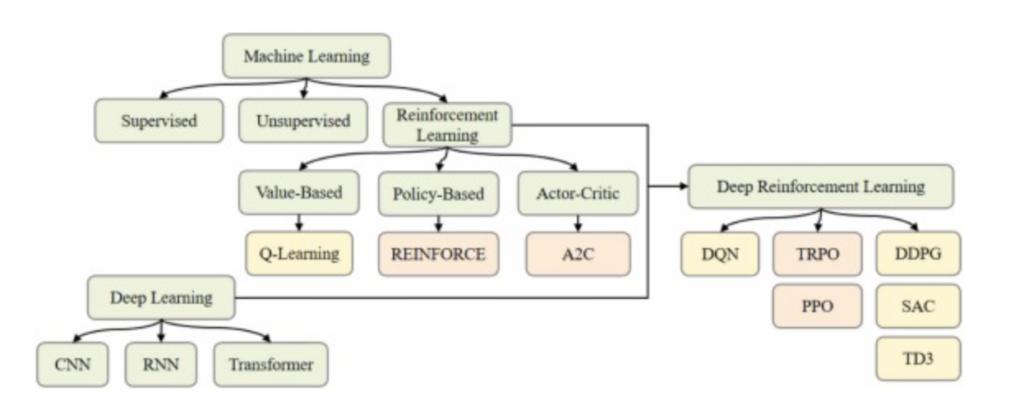
Fig. 2. Un diagramme du chemin de développement de l’apprentissage automatique à l’apprentissage par renforcement profond
2.1.1 . Méthodes fondées sur la valeur
Ces algorithmes visent à apprendre une fonction de valeur qui évalue la valeur de chaque état ou paire état-action. L’algorithme de fonction de valeur le plus classique est l’apprentissage par renforcement Q (Q-learning) ( Watkins et Dayan, 1992 ). Il met à jour itérativement les valeurs action-état (valeurs Q) afin de déterminer indirectement la politique optimale et de sélectionner les actions qui maximisent les récompenses cumulées futures dans chaque état. Ses performances sont faibles avec des états de grande dimension et des espaces d’actions continus (Van Hasselt et Wiering, 2007 ). L’apprentissage par renforcement Q classique est considéré comme inefficace en termes d’échantillonnage pour les grands espaces d’états, car il nécessite de nombreuses interactions pour mettre à jour toutes les paires état-action pertinentes. Sa convergence est théoriquement garantie dans un cadre tabulaire, mais il peut devenir instable et diverger lorsqu’il est associé à des approximants de fonctions comme les réseaux de neurones. En irrigation, l’environnement est défini par des variables continues, ce qui rend impossible l’approche tabulaire requise par l’apprentissage par renforcement Q classique.
2.1.1. Méthodes basées sur la valeur
Ces algorithmes visent à apprendre une fonction de valeur qui évalue la valeur de chaque état ou paire état-action. L’algorithme de fonction de valeur le plus classique est l’apprentissage par renforcement Q (Q-learning) (Watkins et Dayan, 1992). Il met à jour itérativement les valeurs action-état (valeurs Q) afin de déterminer indirectement la politique optimale et de sélectionner les actions qui maximisent les récompenses cumulées futures dans chaque état. Ses performances sont faibles avec des états de grande dimension et des espaces d’actions continus (Van Hasselt et Wiering, 2007). L’apprentissage par renforcement Q classique est considéré comme inefficace en termes d’échantillonnage pour les grands espaces d’états, car il nécessite de nombreuses interactions pour mettre à jour toutes les paires état-action pertinentes. Sa convergence est théoriquement garantie dans un contexte tabulaire, mais il peut devenir instable et diverger lorsqu’il est associé à des approximants de fonctions comme les réseaux de neurones. En irrigation, l’environnement est défini par des variables continues, ce qui rend impossible l’approche tabulaire requise par l’apprentissage par renforcement Q classique.
Les réseaux de neurones profonds (DQN) constituent une extension significative de l’apprentissage par renforcement (Q-learning), utilisant des réseaux de neurones profonds au lieu d’une table Q pour traiter des espaces d’états complexes et de grande dimension, tels que les images et les données de capteurs (Mnih et al., 2015). Les DQN utilisent un tampon de relecture d’expérience pour stocker les paires état-action-récompense passées, ce qui rompt la corrélation temporelle des données et améliore la stabilité de l’apprentissage. De plus, ils emploient un réseau cible avec une fréquence de mise à jour plus faible afin de réduire l’instabilité de l’apprentissage par renforcement. Ce tampon de relecture permet la réutilisation des échantillons. Associé à un réseau cible, il améliore la stabilité de la convergence et prévient les fortes oscillations et la divergence fréquentes dans l’apprentissage par renforcement naïf avec des réseaux de neurones. En général, les DQN présentent un biais de surestimation dans leurs valeurs Q, ce qui peut les conduire à converger vers une politique sous-optimale. Dans le domaine de l’irrigation, ce biais de surestimation est un problème critique, car il peut amener l’agent à choisir systématiquement des actions inefficaces et à prédire de manière imprécise les récompenses à long terme de ces stratégies. Des améliorations ultérieures comme Double Deep Q-Networks ont été développées en découplant la sélection de l’action du processus d’estimation de la valeur pour réduire ce biais optimiste (Jiang et al., 2024).
La fonction de valeur Q est mise à jour par l’équation de Bellman (Éq. (1)). Dans DQN, la fonction de valeur Q est approchée par un réseau de neurones et mise à jour en minimisant la fonction de perte (Éq. (2)). mesure la qualité de la prédiction de la cible par le réseau de neurones (Éq. (3)).
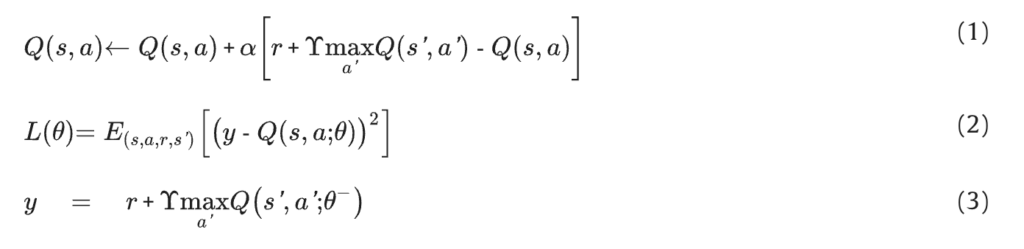
2.1.2. Méthodes basées sur les politiques
Les méthodes de gradient de politique maximisent les récompenses cumulées en optimisant directement les paramètres de la politique et en évitant l’apprentissage basé sur une fonction de valeur. Elles sont performantes dans les espaces d’actions continus et les environnements nécessitant des politiques stochastiques. Une méthode classique, l’algorithme REINFORCE, calcule les mises à jour du gradient des paramètres de la politique à partir des récompenses cumulées, mais souffre d’une forte variance dans l’estimation du gradient et d’une faible efficacité d’apprentissage (Kakade, 2001). Il s’agit d’une méthode de Monte Carlo en politique, qui utilise les données d’un épisode entier pour chaque mise à jour. Sa convergence est souvent lente et instable en raison de la forte variance des estimations du gradient, ce qui peut entraîner des mises à jour de politique erratiques et empêcher la recherche d’un optimum stable.
2.1.3 . Méthodes acteur-critique
Les méthodes acteur-critique combinent le gradient de politique (acteur) et l’estimation de la fonction de valeur (critique). L’acteur met à jour la politique, tandis que le critique estime la fonction de valeur de la politique actuelle afin de réduire la variance des gradients de politique.L’ algorithme Deep Deterministic Policy Gradient (DDPG) ( Lillicrap et al., 2019 ) combine les avantages des gradients de politique déterministes et de l’apprentissage par renforcement (Q-learning), et permet de traiter des espaces d’actions continus. L’acteur suit une politique déterministe, et le critique estime la fonction de valeur par Q-learning. Le critique est mis à jour par la différence temporelle des erreurs en minimisant la fonction de perte ( équation (5) ). L’acteur est mis à jour par des gradients de politique déterministes ( équation (7) ).
2.2 . Application de l’apprentissage par renforcement profond à l’optimisation de l’irrigation
En irrigation, les algorithmes d’apprentissage par renforcement profond (DRL) exploitent des données multidimensionnelles pour entraîner un modèle de réseau neuronal profond. Ce modèle apprend les schémas environnementaux complexes et interagit avec l’environnement pour prendre des décisions d’irrigation. Par un processus continu d’essais et d’erreurs, l’algorithme optimise une stratégie. Il prédit l’impact de différentes quantités d’irrigation sur la croissance des cultures et sélectionne un plan d’irrigation qui maximise à la fois le rendement et l’efficience de l’utilisation de l’eau.L’environnement d’irrigation DRL se compose de l’espace d’états S, de l’espace d’actions A, de la fonction de transition P et de la fonction de récompense R. Lors de la prise de décision en matière d’irrigation, S comprend les paramètres environnementaux, tels que les informations météorologiques (température, précipitations, humidité, prévisions) et les informations sur le sol (humidité, teneur en éléments nutritifs, perméabilité). A représente les options d’irrigation : quantités d’eau (actions ponctuelles ou continues), moment de l’irrigation (immédiate ou différée) et méthodes (irrigation uniforme à grande échelle ou irrigation de précision pour des zones spécifiques). P décrit la transition de l’environnement de l’état actuel à l’état suivant, incluant les mises à jour de l’évapotranspiration des cultures, les variations de l’humidité du sol et les mises à jour des prévisions météorologiques. R correspond à la récompense fournie par l’environnement lors de l’exécution de P.L’agent est l’algorithme d’apprentissage par renforcement profond (DRL) qui met à jour la politique. Différents algorithmes DRL présentent des processus globaux similaires en irrigation intelligente, incluant la perception de l’état, la prise de décision, le retour d’information et la mise à jour de la politique. Les différences résident dans les espaces d’action (discrets ou continus) et les méthodes d’optimisation de la politique.
Le tableau 2 récapitule les algorithmes utilisés, ainsi que leurs avantages, leurs inconvénients et leurs scénarios d’application en irrigation. Les algorithmes « on-policy » et « off-policy » permettent tous deux aux agents d’interagir avec l’environnement pour obtenir de nouveaux retours d’information pendant l’entraînement. Les algorithmes « on-policy » utilisent directement ces retours, tandis que les algorithmes « off-policy » les stockent dans une mémoire tampon de relecture pour un échantillonnage ultérieur.
Tableau 2. Algorithmes DRL dans la planification de l’irrigation.
| Algorithme | Avantages | Inconvénients | Scénarios appropriés en matière d’irrigation | Réf. |
|---|---|---|---|---|
| DQN *, ⸸ | ➢Efficace pour les actions discrètes➢La relecture de l’expérience améliore l’efficacité de l’apprentissage | ➢Espaces d’action continus difficiles à gérer➢biais de surestimation | ▫ Programmation discrète ▫ Choix parmi un ensemble prédéfini de quantités d’irrigation ou de durées fixes ▫ Idéal pour les systèmes simples, basés sur des règles | Elavarasan et Vincent, (2020) Din et al. (2022) Devarajan et coll. (2023) |
| PPO ⁑, † | ➢Flexible pour les actions continues | ➢Coût de calcul élevé, notamment dans les scénarios multi-capteurs | ▫ Fonctionnement continu et discret ▫ Grande flexibilité ▫ Convient pour un réglage précis du volume d’eau (continu) ou pour une sélection parmi des niveaux prédéfinis (discret) | Schulman et coll. (2017) Agyeman et coll. (2024) Ding et Du (2024) |
| DDPG ⁂, ⸸ | ➢Gère les tâches de contrôle continu➢Ajuste avec précision le volume d’eau➢Faible demande de calcul➢Adapté aux appareils aux ressources limitées | ➢Sensible aux hyperparamètres➢Sujet aux optima locaux➢Difficultés liées à une forte incertitude | ▫ Contrôle continu ▫ Adapté aux tâches nécessitant un réglage fin et précis d’une variable continue | Lillicrap et coll. (2019) Ochoa Tamayo (2019) Alibabaei et al. (2022a) |
| SAC ⁂, ⸸ | ➢Gère des environnements dynamiques complexes et des actions continues | ➢Augmentation de la charge de calcul, notamment la charge supplémentaire liée à la régularisation de l’entropie | ▫ Contrôle principalement continu, avec possibilité de contrôle discret ▫ Excellente capacité d’exploration et d’optimisation des volumes d’irrigation continus complexes ▫ Son cadre stochastique est plus adaptable aux scénarios discrets ou hybrides que DDPG | Haarnoja et coll. (2018) Sidiropoulos et Kiourt (2023) Goldenits et al. (2024) |
| A3C ⁂, † | ➢Mises à jour asynchrones➢vitesse d’apprentissage rapide➢Faible demande en mémoire➢Adapté aux appareils aux ressources limitées | ➢Convergence instable dans des environnements à récompenses éparses | ▫ Exploitations agricoles distribuées à grande échelle ▫ Idéal pour la planification parallèle de plusieurs zones ou parcelles d’irrigation indépendantes ▫ Gère les actions continues et discrètes | Shen et al., (2023) |
*Méthode basée sur les valeurs.
⁑ Méthode fondée sur les politiques.
⁂ Méthode acteur-critique.
† Utilisation de l’algorithme en politique.
⸸ Utilisation d’un algorithme hors stratégie.
3. Évaluation de cas d’utilisation exemplaires de l’apprentissage par renforcement profond dans l’optimisation de l’ irrigation
L’apprentissage par renforcement profond (DRL) a connu des progrès considérables dans de nombreux domaines, mais reste relativement peu étudié dans le domaine de l’irrigation. La précision du DRL dépend fortement de la conception de l’environnement, qui détermine directement la capacité de l’agent à comprendre correctement le problème et à apprendre la stratégie optimale. En irrigation agricole, la modélisation environnementale est complexe en raison de la dynamique de l’humidité du sol, des variations météorologiques et de la croissance des cultures, ainsi que de la dimensionnalité, de la diversité et de la latence élevées de ces facteurs. On considère que la poursuite des recherches et la promotion du DRL en irrigation peuvent apporter des solutions innovantes pour un développement agricole durable. Ce travail examine plusieurs applications du DRL en irrigation, notamment deux catégories classiques : l’environnement basé sur des simulateurs de croissance des cultures, qui utilise un environnement virtuel pour le pré-entraînement des modèles et explore la stratégie d’irrigation optimale au cours du cycle de croissance simulé ; et l’environnement basé sur des données de capteurs en temps réel, qui utilise directement les informations collectées par les capteurs (température, humidité, humidité du sol, luminosité, etc.) pour construire un environnement dynamique et ajuster la stratégie d’irrigation.
3.1 . Méthodes basées sur des modèles de croissance des cultures
Le besoin de décisions d’irrigation précises pour la croissance des cultures a conduit de nombreux chercheurs à valider l’efficacité de l’apprentissage par renforcement profond (DRL) dans ce domaine à l’aide de simulateurs.
Overweg et al. (2021) ont introduit CropGym, un environnement DRL dédié à la gestion des cultures.
Ashcraft et Karra (2021) ont mené des travaux similaires, utilisant un simulateur de croissance des cultures (le modèle SIMPLE) combiné à l’interface OpenAI Gym pour construire un environnement virtuel. Ce simulateur fournit des transitions d’état et un système de récompenses. Il interagit avec un agent DRL (PPO) afin d’optimiser le rendement des cultures tout en minimisant l’utilisation des ressources (
Fig. 3 ). Le simulateur permet de créer un environnement virtuel de haute fidélité et de réduire considérablement les coûts d’entraînement. La littérature souligne également les limites de cette méthode. Lors de la capture des dynamiques réelles, les simulateurs supposent souvent un seul type de sol. Prenons l’exemple d’un champ réel composé à 40 % de limon sableux et à 60 % de limon argileux : un agent DRL entraîné sur un modèle de sol moyen apprendra une seule stratégie, entraînant un sous-arrosage des zones sableuses et un sur-arrosage des zones argileuses. Il ne s’agit pas d’une simple inefficacité, mais d’une erreur d’appréciation des besoins réels de la culture.
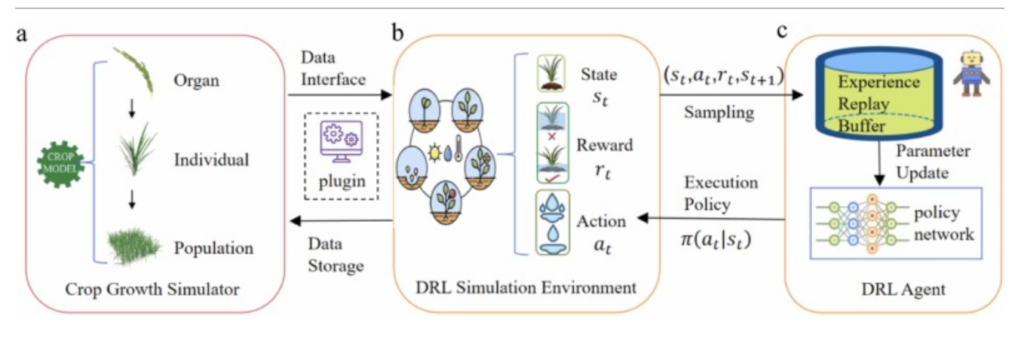
Fig. 3. Processus d’interaction entre l’apprentissage par renforcement profond (DRL) et un simulateur de croissance des cultures. Le simulateur de croissance des cultures (a) est intégré dans un environnement de simulation DRL (b) via une interface de données. L’agent DRL (c) obtient l’état actuel.sélectionne une action dans l’environnement.utilisant son réseau de politiqueset reçoit une récompense immédiateLe tuple d’expérience est ensuite utilisé pour l’entraînement afin d’optimiser la politique de l’agent.Il est important de prendre en compte les facteurs météorologiques, car une augmentation des précipitations peut entraîner un mauvais drainage des sols et un ruissellement excessif.
Chen et al. (2021) ont utilisé des prévisions météorologiques pour déterminer dynamiquement les besoins en irrigation, en développant un système de décision d’optimisation de l’irrigation du riz basé sur l’apprentissage par renforcement profond (DRL). Ils ont combiné des données de prévisions météorologiques (précipitations, température et rayonnement solaire) avec des informations sur la profondeur de l’eau du sol pour construire un modèle de processus de décision markovien (MDP). Les états du modèle comprennent la profondeur de l’eau du sol, les prévisions de précipitations futures et les seuils d’irrigation. Les actions du modèle consistent en trois niveaux d’irrigation discrets (0 %, 50 % et 100 % de la demande en irrigation). L’étude a développé un environnement de simulation virtuelle basé sur un modèle de bilan hydrique (
Éq. (11) ), intégrant les processus de précipitation (P), d’irrigation (I), de drainage vertical (D), d’évapotranspiration (ET) et de ruissellement de surface (R) pour simuler les variations dynamiques de l’humidité du sol.Le système apprend les stratégies optimales grâce à son interaction avec l’environnement de simulation via l’algorithme DQN et exploite les prévisions météorologiques pour anticiper les précipitations et adapter l’irrigation en conséquence. L’irrigation ainsi optimisée permet d’économiser 23 mm d’eau, de réduire le drainage de 21 mm et de diminuer la durée d’irrigation d’un facteur 1,0 en moyenne, sans impact significatif sur le rendement.
Alibabaei et al. (2022a) ont combiné des données climatiques de la région de Fadagosa au Portugal avec un simulateur de cultures DSSAT (Fig. 4a ) doté d’une architecture LSTM bidirectionnelle (BLSTM) ( Fig. 4b ) comme environnement d’apprentissage par renforcement profond (DRL) ( Fig. 4c ). Le BLSTM a été utilisé pour prédire des variables à court terme (par exemple, l’humidité du sol) et à long terme (par exemple, le rendement). L’agent DQN entraîné ( Fig. 4d ) a automatiquement prévenu le gaspillage d’eau en début de saison et le stress hydrique des plantes en fin de saison. De plus, le modèle entraîné peut ajuster les quantités d’irrigation en fonction des variations climatiques et des précipitations saisonnières. Alibabaei et al. (2022b) ont introduit un modèle DRL basé sur des politiques, Advantage Actor-Critic (A2C), issu de recherches sur l’irrigation agricole optimisées par DQN ( Fig. 4e ). Le modèle utilise l’humidité du sol (SWTD), les variables climatiques et le volume de la dernière irrigation comme états, et ajuste dynamiquement 12 actions d’irrigation discrètes via un réseau de politiques afin d’optimiser simultanément la consommation d’eau, le rendement et le revenu net. A2C surpasse DQN en termes de consommation d’eau (20 à 23 % de moins), d’adaptabilité au changement climatique et de stabilité d’apprentissage. DQN surpasse A2C en termes de rendement et de revenu net (3 à 7 % de plus). Comparé aux méthodes d’irrigation par seuil traditionnelles, A2C réduit significativement la consommation d’eau (45 à 50 % de moins) et augmente sensiblement le revenu net. L’étude a uniquement pris en compte les données climatiques.
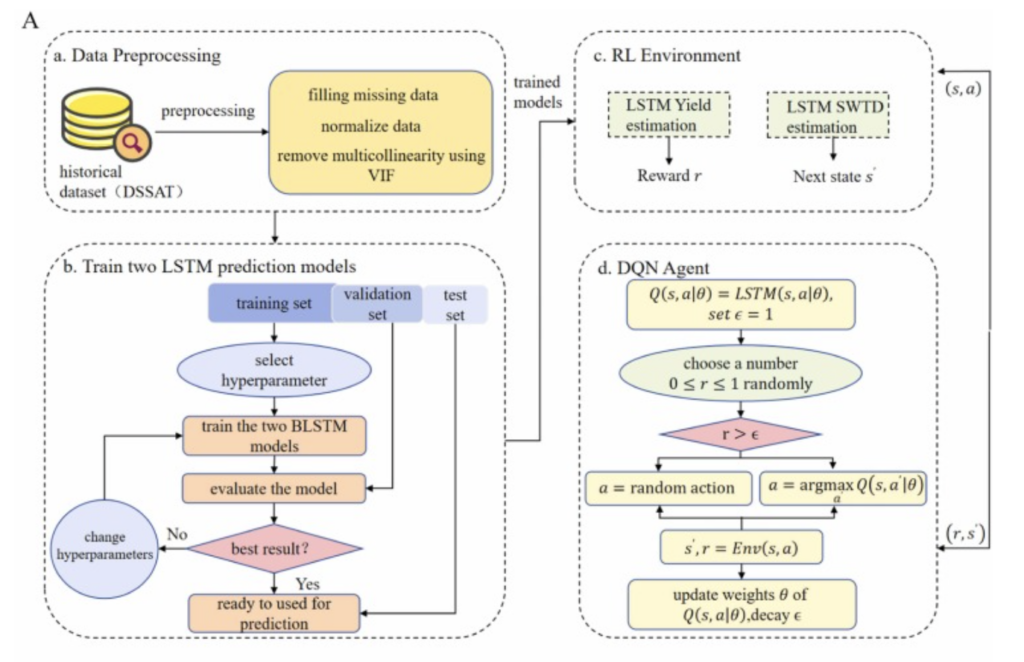
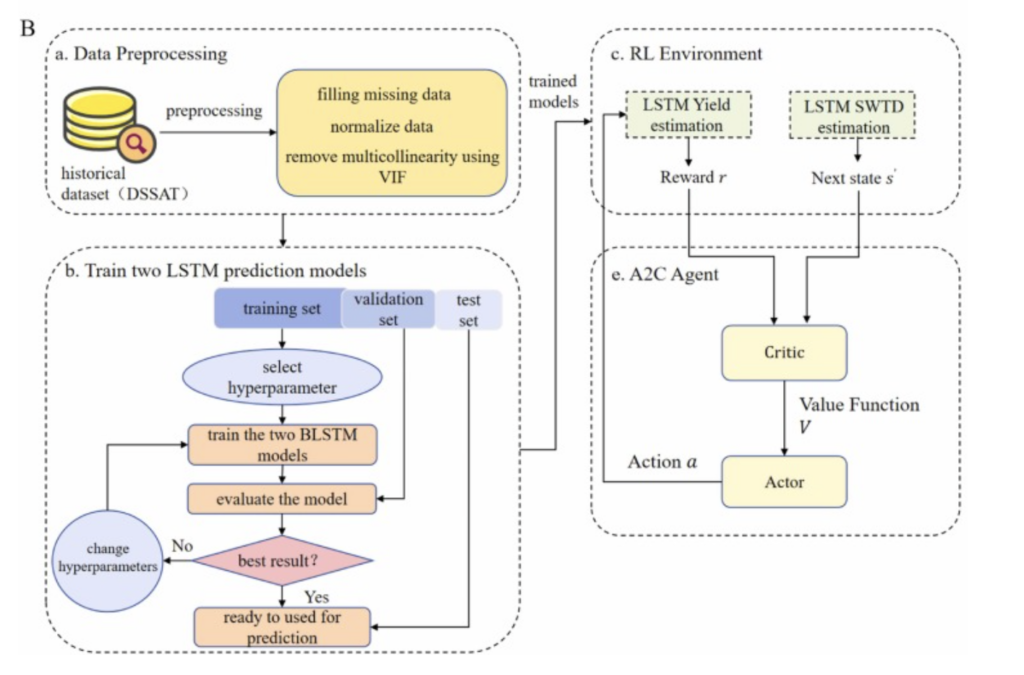
Figure 4. Comparaison des méthodes (A) DSSAT + BLSTM + agent DQN et (B) DSSAT + BLSTM + agent A2C pour l’optimisation de l’irrigation. Ces deux méthodes comprennent (a) le prétraitement des données, (b) l’entraînement de deux modèles de prédiction LSTM et (c) l’interaction avec l’environnement DRL. La principale différence réside dans l’utilisation (d) d’un agent DQN contre (e) d’un agent A2C.
| Étude | Recadrer | Algorithme DRL | Type d’environnement | Principaux résultats rapportés (par rapport à la valeur de référence) | Scénarios appropriés |
|---|---|---|---|---|---|
| Zhong (2025) | Blé Maïs Tomates | CNN-LSTM+DRL | Fondé sur les données | Blé : + 22,5 % de rendement et − 18,9 % d’eau ; Maïs : + 28,1 % de rendement et − 24,5 % d’eau ; Tomates : + 31,4 % de rendement et − 29,8 % d’eau | Mettre l’accent sur la composante prédictive dans un cadre d’irrigation DRL |
| Ding et Du (2024) | Amande | Politiques fondées sur (DRLIC) | Fondé sur les données | Jusqu’à 9,52 % d’économies d’eau par rapport à un système basé sur l’évapotranspiration. | Utilisation novatrice d’un simulateur rapide et de mécanismes de sécurité, mais le simulateur lui-même est très gourmand en données. |
| Chen et al. (2023) | Coton | RL (non spécifié) | Simulation | + 28,6 % de rendement et − 16,2 % d’eau | Application et validation directes sur coton, fournissant un point de référence clé spécifique au domaine |
| Saikai et al. (2023) | Blé | RENFORCER | APSIM | Ont systématiquement surpassé les règles conventionnelles, avec une amélioration des indicateurs de performance pouvant atteindre 17 %. | Gérer efficacement les données de capteurs multidimensionnelles, en supposant une alimentation en eau illimitée |
| Alibabaei et al. (2022a) | Tomate | DQN | DSSAT + BLSTM | + 11 % de rendement et − 20 % à −30 % d’eau | Validation solide avec DSSAT haute fidélité, mais l’environnement repose sur une couche BLSTM prédictive |
| Alibabaei et al. (2022b) | Tomate | DQN | DSSAT + BLSTM | A2C : − 21,5 % d’eau par rapport à DQN et DQN : + 3,5 % de rendement par rapport à A2C | Comparaison directe des politiques en vigueur (A2C) et hors politique (DQN) |
| Chen et al. (2021) | Riz | DQN | Modèle d’équilibre hydrique | -23 mm d’eau et -21 mm de drainage tout en maintenant le rendement et en réduisant la fréquence d’irrigation | Intégration des prévisions météorologiques pour une planification proactive, mais dans un environnement simplifie |
Références
- Achiam et al., 2017Achiam, J., Held, D., Tamar, A., Abbeel, P., 2017. Optimisation de politique contrainte.Google Scholar
- Adutwum et al., 2025Adutwum, GK, Chung, ES, Song, YH, 2025. Réseaux neuronaux graphiques spatio-temporels informés par la physique pour la prédiction de l’évapotranspiration : le cas de la péninsule coréenne.Google Scholar
- Agyeman et al., 2024BT Agyeman , M. Naouri , WM Appels , J. Liu , SL ShahMPC multi-agents basé sur l’apprentissage pour la planification de l’irrigationPratique de l’ingénierie de contrôle , 147 ( 2024 ) , Article 105908Voir le PDFVoir l’article Voir dans Scopus Google Scholar
- Ahmed et al., 2023Z. Ahmed , D. Gui , G. Murtaza , L. Yunfei , S. AliAperçu de la gestion intelligente de l’irrigation pour améliorer la productivité de l’eau dans les zones arides face aux changements climatiquesAgronomie , 13 ( 2023 ) , p. 2113 , 10.3390/agronomy13082113Voir dans Scopus Google Scholar
- Al-Ghobari et Dewidar, 2021H. Al-Ghobari , AZ DewidarÉtude comparative d’un système d’irrigation pivot standard et d’un système pivot modifié par les producteurs pour évaluer le coefficient d’uniformité et la distribution de l’eauAgron. , 11 ( 2021 ) , p. 1675 , 10.3390/agronomy11081675Voir dans Scopus Google Scholar
- Alibabaei et al., 2022aK. Alibabaei , PD Gaspar , E. Assunção , S. Alirezazadeh , TM LimaOptimisation de l’irrigation à l’aide d’un modèle d’apprentissage par renforcement profond : étude de cas sur un site au PortugalAgricole. Gestion de l’eau. , 263 ( 2022 ) , article 107480 , 10.1016/j.agwat.2022.107480Voir le PDFVoir l’article Voir dans Scopus Google Scholar
- Alibabaei et al., 2022bK. Alibabaei , PD Gaspar , E. Assunção , S. Alirezazadeh , TM Lima , VNGJ Soares , JMLP CaldeiraComparaison de l’apprentissage par renforcement profond A2C avec stratégie et du DQN sans stratégie pour l’optimisation de l’irrigation : une étude de cas sur un site au PortugalComputers , 11 ( 2022 ) , p. 104 , 10.3390/computers11070104Voir dans Scopus Google Scholar
- Arulkumaran et al., 2017K. Arulkumaran , député Deisenroth , M. Brundage , AA BharatUn bref aperçu de l’apprentissage par renforcement profondIEEE Signal Process. Mag. , 34 ( 2017 ) , pp. 26 – 38 , 10.1109/MSP.2017.2743240Voir dans Scopus Google Scholar
- Ashcraft et Karra, 2021Ashcraft, C., & Karra, K. 2021. Optimisation du rendement des cultures assistée par l’apprentissage automatique. Prépublication arXiv : arXiv:2111.00963.Google Scholar
- Ayaz et al., 2019M. Ayaz , M. Ammad-Uddin , Z. Sharif , A. Mansour , E.-HM AggouneAgriculture intelligente basée sur l’Internet des objets (IdO) : vers des champs qui parlentIEEE Access , 7 ( 2019 ) , p. 129551-129583 , 10.1109 / ACCESS.2019.2932609Voir dans Scopus Google Scholar
- Bellemare et al., 2017Bellemare, MG, Dabney, W., Munos, R., 2017. Une perspective distributionnelle sur l’apprentissage par renforcement.Google Scholar
- Bellman, 1966R. BellmanProgrammation dynamiqueSci. , 153 ( 3731 ) ( 1966 ) , pp. 34 – 37Voir dans Crossref et Scopus Google Scholar
- Bellman et Dreyfus, 2015RE Bellman , SE DreyfusProgrammation dynamique appliquée , Princet. Univ. Press ( 2015 )Google Scholar
- Bertsekas, 2019Bertsekas, DP, 2019. Un cours d’apprentissage par renforcement, 2e édition.Google Scholar
- Bhat et Huang, 2021SA Bhat , N.-F. HuangRévolution du Big Data et de l’IA dans l’agriculture de précision : état des lieux et enjeuxIEEE Access , 9 ( 2021 ) , p. 110209-110222 , 10.1109 / ACCESS.2021.3102227Voir dans Scopus Google Scholar
- Browne et al., 2012CB Browne , E. Powley , D. Whitehouse , SM Lucas , PI Cowling , P. Rohlfshagen , S. Tavener , D. Perez , S. Samothrakis , S. ColtonÉtude comparative des méthodes de recherche arborescente de Monte CarloIEEE Trans. Comput. Intell. AI Games , 4 ( 2012 ) , p. 1-43 , 10.1109 / TCIAIG.2012.2186810Voir dans Scopus Google Scholar
- Bu et Wang, 2019F. Bu , X. WangUn système IoT d’agriculture intelligente basé sur l’apprentissage par renforcement profondFuture Gener . Comput. Syst. , 99 ( 2019 ) , p. 500-507 , 10.1016 /j.future.2019.04.041Voir le PDFVoir l’article Voir dans Scopus Google Scholar
- Bwambale et al., 2022E. Bwambale , FK Abagale , GK AnornuStratégies intelligentes de surveillance et de contrôle de l’irrigation pour améliorer l’efficacité de l’utilisation de l’eau en agriculture de précision : une revueAgricole. Gestion de l’eau. , 260 ( 2022 ) , article 107324 , 10.1016/j.agwat.2021.107324Voir le PDFVoir l’article Voir dans Scopus Google Scholar
- Campoverde et al., 2021LMS Campoverde , M. Tropea , F. De RangoUn système intelligent de gestion de l’irrigation basé sur l’IoT et utilisant l’apprentissage par renforcement modélisé par un processus de décision markovien. Présenté lors de la 25e conférence internationale IEEE/ACM de 2021.Symposium sur la simulation distribuée et les applications temps réel DS-RT , IEEE ( septembre 2021 ) , p . 1-4Crossref Google Scholar
- Chen et al., 2021M. Chen , Y. Cui , X. Wang , H. Xie , F. Liu , T. Luo , S. Zheng , Y. LuoUne approche d’apprentissage par renforcement pour la prise de décision en matière d’irrigation du riz à l’aide de prévisions météorologiquesAgricole. Gestion de l’eau. , 250 ( 2021 ) , Article 106838 , 10.1016/j.agwat.2021.106838Voir le PDFVoir l’article Voir dans Scopus Google Scholar
- Chen et al., 2025Y. Chen , M. Lin , Z. Yu , W. Sun , W. Fu , L. HeAmélioration de l’irrigation du coton grâce à l’apprentissage par renforcement acteur-critique distributionnelAgricole. Gestion de l’eau. , 307 ( 2025 ) , article 109194 , 10.1016/j.agwat.2024.109194Voir le PDFVoir l’article Voir dans Scopus Google Scholar
- Chen et al., 2023Y. Chen , Z. Yu , Z. Han , W. Sun , L. HeUn système de prise de décision pour l’irrigation du coton basé sur une stratégie d’apprentissage par renforcementAgronomie , 14 ( 2023 ) , p. 11 , 10.3390/agronomy14010011Google Scholar
- Dayan et Balleine, 2002P. Dayan , BW BalleineRécompense, motivation et apprentissage par renforcementNeuron , 36 ( 2 ) ( 2002 ) , pp. 285 – 298Voir le PDFVoir l’article Voir dans Scopus Google Scholar
- Deng et al., 2017Y. Deng , F. Bao , Y. Kong , Z. Ren , Q. DaiApprentissage par renforcement direct profond pour la représentation et le trading de signaux financiersIEEE Trans. Neural Netw. Learn. Syst. , 28 ( 2017 ) , pp. 653 – 664 , 10.1109/TNNLS.2016.2522401Voir dans Scopus Google Scholar
- Devarajan et al., 2023GG Devarajan , SM Nagarajan , U. Ghosh , W. AlnumayDDNSAS : Réseau d’apprentissage par renforcement profond basé sur l’apprentissage Q profond pour un système d’agriculture intelligenteSystèmes informatiques durables , 39 ( 2023 ) , Article 100890Voir le PDFVoir l’article Voir dans Scopus Google Scholar
- Din et al., 2022A. Din , MY Ismail , B. Shah , M. Babar , F. Ali , SU BaigUn contrôle de couverture de zone multi-agents basé sur l’apprentissage par renforcement profond pour l’agriculture intelligenteIngénierie informatique et électrique , 101 ( 2022 ) , Article 108089Voir le PDFVoir l’article Voir dans Scopus Google Scholar
- Ding et Du, 2022Ding, X., Du, W., 2022. DRLIC : apprentissage par renforcement profond pour le contrôle de l’irrigation. Dans : 21e Conférence internationale ACM/IEEE sur le traitement de l’information dans les réseaux de capteurs (IPSN), IEEE, Milan, Italie, p. 41-53 . https://doi.org/10.1109/IPSN54338.2022.00011Google Scholar
- Ding et Du, 2024X. Ding , W. DuOptimisation de l’efficacité de l’irrigation grâce à l’apprentissage par renforcement profond sur le terrainACM Trans. Sen. Netw. , 20 ( 2024 ) , p. 1-34 , 10.1145 / 3662182Google Scholar
- Elavarasan et Vincent, 2020D. Elavarasan , PD VincentPrédiction du rendement des cultures à l’aide d’un modèle d’apprentissage par renforcement profond pour des applications agricoles durables
