




Apprentissage par renforcement déterministe prenant en compte le délai
Abstrait
L’apprentissage par renforcement (RL) a considérablement ouvert la voie au contrôle robotique au cours de la dernière décennie. De ce fait, l’intégration du contrôle robotique basé sur le RL et de la téléopération a suscité un vif intérêt chez les chercheurs. Tout cadre de RL repose sur une communication appropriée entre l’environnement et l’agent, via l’observation et l’action. Or, la téléopération peut introduire des délais aléatoires dans ce processus de communication. Le contrôle robotique sous de telles contraintes demeure un domaine inexploré de l’apprentissage par renforcement. Nous proposons une approche novatrice pour atteindre cet objectif, tout en gérant les délais dans un contexte de RL, grâce à une structure de processus de décision markovien (MDP) adaptée. Notre algorithme apprend une politique déterministe et peut s’adapter à des environnements de contrôle, notamment de manipulation robotique, en utilisant des observations enrichies d’informations proprioceptives. Nous présentons méthodiquement les ajustements théoriques apportés à un algorithme dominant hors stratégie existant afin de démontrer la compétence de notre algorithme, preuves de convergence à l’appui. Nos expérimentations avec la suite DeepMind Control illustrent des résultats significatifs démontrant les capacités de notre algorithme à apprendre dans des environnements complexes grâce à un RL prenant en compte les délais.
Mots clés
- Apprentissage par renforcement
- Délai aléatoire
- apprentissage par renforcement profond
- Apprentissage par renforcement prenant en compte le délai
- Manipulation robotique
1. Introduction
Le cadre de l’apprentissage par renforcement (RL) repose principalement sur deux entités : l’agent et l’environnement. Le processus d’apprentissage du RL implique la communication des actions de l’agent vers l’environnement et des observations de l’environnement vers l’agent. Bien que ce processus de communication soit considéré comme instantané dans un contexte idéal, il peut ne pas l’être dans certaines situations, comme la téléopération. Dans ce cas, un délai peut survenir lors de la communication des actions et des observations entre l’agent et l’environnement. Ce scénario est illustré dans la figure 1. Ce contexte, déjà étudié [1] , [2] , concerne le domaine du RL où les actions ne sont pas appliquées instantanément dans l’environnement et où les observations ne sont pas instantanément capturées par l’agent. Dans de tels cas, diverses mesures ont été mises en œuvre pour compenser le délai de capture des actions et des observations. Parmi celles-ci, on retrouve fréquemment l’hypothèse de délais constants [1] , [3] et la modélisation idéale des observations futures dans le but de compenser ce délai [4] , [5] . Cependant, ces types de techniques n’ont pas permis de gérer les environnements complexes comportant de grands espaces d’états et d’actions tout en gérant ledit délai.En apprentissage par renforcement (RL), les algorithmes hors stratégie comme Deep Deterministic Policy Gradient (DDPG) [6] , Twin Delayed DDPG (TD3) [7] et Soft Actor–Critic (SAC) [8] excellent en contrôle continu, mais rencontrent des difficultés d’apprentissage en présence de délais, car ils supposent des actions et des observations instantanées. Dans un environnement retardé comme celui illustré à la figure 1 , il peut être avantageux d’exploiter la connaissance de la dynamique retardée pour garantir un processus d’apprentissage adéquat et un contrôle ininterrompu de l’environnement non retardé. Le cadre Delay-Correcting Actor–Critic (DCAC) [9] , développé par Bouteiller et al., a ouvert la voie à ce type d’approche de contrôle RL sans planification et prenant en compte les délais. Basé sur SAC, DCAC attend des informations sur les caractéristiques de l’environnement sous forme de tableau unidimensionnel. Cette utilisation des observations est appelée apprentissage basé sur les caractéristiques. Cependant, l’ajustement automatique de l’entropie de SAC peut entraîner un effondrement prématuré de l’entropie lors de tâches complexes telles que la manipulation robotique [10] . Ces environnements renvoient des informations proprioceptives de dimensionnalité supérieure dans l’espace d’état. Nous visons donc à étendre le cadre DCAC avec une base DDPG, créant ainsi le premier algorithme de commande prenant en compte le délai dans le domaine déterministe.Dans cet article, nous proposons DCAC-v2, un nouvel algorithme d’apprentissage par renforcement (RL) capable de résoudre le problème susmentionné. Pour gérer à la fois les comportements complexes et la latence, nous nous appuyons sur le cadre DDPG, ce qui permet à notre algorithme d’apprendre une politique déterministe. DCAC-v2 reste centré sur le processus de décision markovien à délai aléatoire (RDMDP) formulé dans DCAC, qui prend en compte les délais d’action et d’observation, ainsi que l’historique des actions dans l’espace d’états, comme détaillé dans la définition 1. Les techniques de gestion du délai intégrées à l’algorithme proposé sont illustrées dans la section 2. Il est également important de noter que nous utilisons un bruit d’exploration programmé [10] pour mener une exploration efficace lors de l’entraînement, en éliminant l’exploration basée sur l’entropie de SAC. Cette stratégie d’exploration garantit que l’agent explore largement l’environnement initialement, puis converge vers un comportement ciblé, projetant ainsi un comportement déterministe.
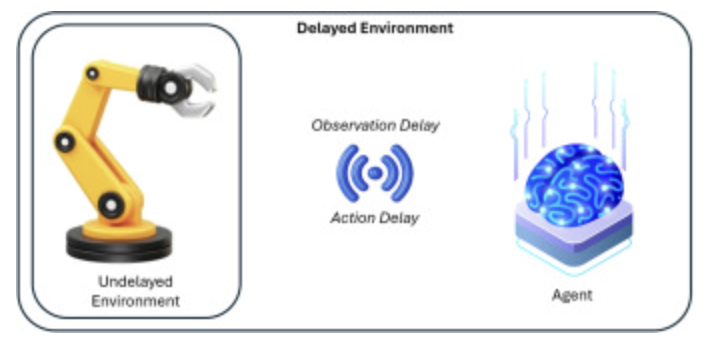
2. Contexte
La formulation du RDMDP est basée sur la structure MDP commune où un environnementest modélisé avec un espace d’étatet un espace d’action, ainsi qu’une distribution d’état initialeet une distribution de transitionNous considérons des environnements où les espaces d’états et d’actions sont continus. Le RDMDP étend le MDP standard pour fournir l’environnement augmenté, ainsi que les distributions de délais et un espace d’états augmenté., une distribution d’état initial modifiéeet une distribution de transition étendue.L’espace d’état augmentéconsiste en l’observation retardée, un ensemble d’actions, et les délais d’observation et d’action, qui sont numériques. Le délai d’observation et le délai d’action sont notés paret, respectivement. Le tampon d’action est représenté par.Elle contient la valeur de la combinaison maximale possible des délais d’observation et d’action. Il est important d’accorder une attention particulière à la distribution de transition au sein d’un RDMDP. Celle-ci contient principalement la distribution des délais d’observation.et la distribution de transition pour le tampon d’actionLa distribution du délai d’observationLe modèle décrit l’évolution des délais d’observation et répète les observations si aucune nouvelle n’est disponible, ce qui implique que la croissance maximale de ce délai ne peut être que de un, d’un pas de temps à l’autre. Enfin, la distribution de transition suit la distribution, qui illustre l’évolution de l’observation elle-même, ainsi que la récompense et le délai d’action. Cette distribution est encore amplifiée dans l’équation.
3. DCAC -v2 : Apprentissage par renforcement déterministe prenant en compte le délai
Comme mentionné précédemment, DCAC utilise SAC comme algorithme de base, lequel apprend une politique intégrant l’entropie. Afin de traiter des environnements complexes tels que les tâches de manipulation robotique, nous nous attachons à surmonter les limitations que SAC peut engendrer pour un contrôle optimal. Bien que SAC maximise l’entropie de la politique, ce qui se traduit par une exploration étendue, l’ajustement automatique de l’entropie peut, dans certains cas, provoquer un effondrement prématuré de l’entropie, comme l’ont souligné Yarats et al.
[10] . Cette observation nous préoccupe, car nous souhaitons étendre nos recherches à des tâches plus complexes, avec des espaces d’états plus vastes dans le domaine robotique, contenant des informations de dimensionnalité supérieure. Ceci requiert un algorithme performant en exploration, capable en outre de gérer le délai.Dans un premier temps, nous intégrons DDPG à la structure RDMDP pour former DCAC-v2. Le remplacement de SAC par DDPG vise à pallier l’inconvénient lié à l’ajustement de l’entropie, même si nos expérimentations reposent sur des observations basées sur les caractéristiques. La stratégie d’exploration est donc modifiée pour favoriser l’apprentissage d’une politique déterministe. Pour l’exploration, nous adoptons une stratégie similaire à celle d’Amos et al.
[12], où l’exploration est planifiée en fonction des différentes phases d’apprentissage. Ce calendrier d’exploration induit un comportement plus stochastique en début d’entraînement, permettant une exploration plus rigoureuse de l’environnement. Par la suite, la politique devient plus déterministe afin de maîtriser un comportement jugé plus fiable. Le calendrier d’exploration est conçu pour décroître linéairement la variance.comme:
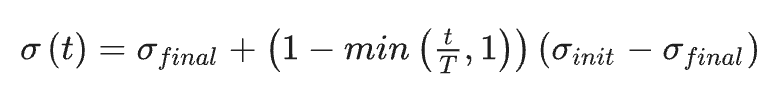
4. Expériences
Nous menons nos expérimentations à l’aide d’environnements de contrôle continu de la suite DeepMind Control [14] . Il est à noter que, dans l’étude originale, l’algorithme DCAC a été testé avec des environnements OpenAI Gym [15] . Afin de préserver la gestion des observations au sein de la structure algorithmique, nous intégrons une interface permettant de convertir les structures d’environnement de la suite DeepMind Control en celles des environnements OpenAI Gym. Nous utilisons pour cela l’interface dmc2gym [16] , où la dynamique de l’environnement reste inchangée tandis que l’interface d’interaction environnement-algorithme est similaire au fonctionnement des environnements OpenAI Gym.Nous comparons principalement les performances de l’algorithme DCAC-v2 à celles des algorithmes DCAC et SAC originaux dans le cadre du RDMDP. La principale différence entre DCAC et SAC réside dans le fait que le critique de SAC estime la valeur de l’action., tandis que DCAC fonctionne avec la valeur d’étatL’estimation [9] indique que DCAC et SAC sont tous deux soumis aux contraintes de la structure RDMDP. Par conséquent, les résultats serviront directement de référence pour le contrôle RL déterministe dans le domaine retardé (basé sur RDMDP). L’expérimentation se déroule en deux phases : premièrement, nous entraînons les algorithmes avec un ensemble de tâches de contrôle courantes, utilisées pour illustrer les performances de DCAC dans l’étude originale. Nous sélectionnons avec soin un sous-ensemble des mêmes environnements au sein de la suite DeepMind Control Suite (initialement utilisée via OpenAI Gym) afin de garantir l’équité de l’expérimentation. Nous exécutons quatre tâches de contrôle courantes, chaque expérience comportant 500 itérations de 2 000 étapes chacune (soit un total d’un million d’étapes). Ces quatre tests sont menés avec des caractéristiques de délai similaires pour les algorithmes SAC, DCAC et DCAC-v2 : des délais d’observation et d’action de deux étapes, aléatoires.La deuxième phase consiste en la tâche de manipulation robotique de base proposée par la suite logicielle DeepMind Control Suite, conçue autour du Kinovo.Manipulateur robotique à 6 degrés de liberté. Cette tâche, appelée « Atteindre une cible », consiste pour le manipulateur robotique à diriger son effecteur terminal vers une zone cible sphérique dans son espace de travail. Comparée aux tâches de contrôle classiques, cette tâche présente un espace d’états de dimensionnalité plus élevée. Quantitativement, cet espace d’états comporte 45 éléments, contre 4 pour une tâche de contrôle courante comme « Reacher Easy »
[14] . Par conséquent, nous effectuons l’entraînement de l’environnement robotique sur 600 itérations, chacune comprenant 5 000 étapes, soit un total de 3 000 000 étapes. Nous réalisons deux tests dans cette phase : premièrement, nous laissons les algorithmes évoluer dans l’environnement avec des délais constants (,), puis nous introduisons des conditions de délai extrêmes pour tester la robustesse de DCAC-v2. Pour ce test de robustesse, nous étendons le délai d’action à un délai aléatoire de 2 étapes., tout en augmentant le délai d’observation à partir d’un délai aléatoire de 3 étapesPassons maintenant à l’étape en 5 étapes.et enfin les 9 étapesDans le cas final d’un délai d’observation aléatoire de 9 étapes, l’algorithme gérera des délais allant jusqu’à 320 ms lors du traitement des observations. Le taux de réussite de toutes les tâches, y compris les tâches de contrôle communes, est mesuré et comparé au rendement moyen total sur l’ensemble des itérations. Les caractéristiques expérimentales sont résumées dans le tableau 1 .
Tableau 1. Expériences réalisées sur les caractéristiques de délai.
| Environnement | Nombre de marches | Caractéristiques du délai |
|---|---|---|
| Tâches de contrôle courantes | ||
| Promenade des marcheurs | 1 000 000 | , |
| Reacher Easy | 1 000 000 | , |
| Hopper Hop | 1 000 000 | , |
| Marche humanoïde | 1 000 000 | , |
| Tâches de manipulation robotique | ||
| Site d’accès | 3 000 000 | , |
| Site d’accès – Retard prolongé | 3 000 000 | , , , |
5. Travaux connexes
L’apprentissage par renforcement (RL) et l’apprentissage par renforcement dynamique (DRL) avec délai ont été récemment testés et évalués, apportant plusieurs contributions, notamment à mesure que la télécommande se généralise dans les applications [17] , [18] , [19] , [20] . Dans ces travaux, on observe principalement un RL avec délai constant, tandis que l’apprentissage par renforcement prenant en compte les délais aléatoires a connu un développement plus rapide.Chen et al. [21] ont développé un cadre d’apprentissage par renforcement basé sur un modèle prenant en compte le délai pour les tâches de contrôle continu. Ils ont proposé une définition formelle du processus de décision markovien (MDP) prenant en compte le délai et ont démontré sa transformation en un MDP standard à états augmentés grâce au processus de récompense markovien. Sans effort supplémentaire, ce cadre a permis d’intégrer un délai à plusieurs étapes dans les modèles de systèmes appris. Des simulations ont validé les capacités généralisées de cette méthode lors de son transfert entre des systèmes présentant différents niveaux de délai, ainsi qu’une formation plus efficace. Li et al. [22] ont introduit une méthode d’apprentissage par renforcement utilisant des données retardées pour l’apprentissage de solutions approchées aux problèmes de commande de suivi optimal (OTCP) de systèmes non linéaires de grande dimension. Cette méthode est basée sur la programmation dynamique adaptative incrémentale. Elle convertit un OTCP récalcitrant en plusieurs sous-OTCP de sous-systèmes incrémentaux de faible dimension, construits à partir de données retardées et résolus par une structure de critique parallèle. Des expériences menées sur un manipulateur à 3 degrés de liberté ont validé l’efficacité de cette stratégie, notamment sa stabilité et sa convergence. Han et al. [23] a introduit un cadre d’apprentissage par renforcement hors stratégie capable de gérer les récompenses différées, les récompenses immédiates n’étant pas disponibles instantanément après l’exécution d’une action. La méthode exploite une nouvelle formulation de la fonction Q avec convergence théorique garantie et est étendue aux tâches de grande dimension grâce à la règle de décomposition HC (informations sur l’état historique et actuel), où l’accès direct à la valeur Q est complexe. Des expériences simulées ont été menées à l’aide d’OpenAI Gym, pour réaliser un contrôle continu dans un contexte de récompense différée, et la méthode a démontré des performances robustes et efficaces.
6. Conclusion et perspectives
Dans cette étude, nous avons abordé le problème du contrôle par apprentissage par renforcement prenant en compte les délais. Nous avons proposé un nouvel algorithme, DCAC-v2, qui intègre DDPG pour apprendre avec succès une politique de contrôle déterministe tout en gérant les délais aléatoires dans l’interaction agent-environnement.L’expérimentation a été menée avec des tâches de contrôle courantes et des tâches complexes de manipulation robotique à l’aide de la suite de contrôle DeepMind. Quatre tâches de contrôle courantes équivalentes de cette suite ont été entraînées selon le protocole expérimental mis en œuvre dans l’étude originale de DCAC avec les environnements OpenAI Gym, ainsi qu’avec SAC dans le cadre RDMDP. Pour la majorité des tâches, DCAC-v2 surpasse SAC et DCAC, démontrant des performances significatives dans la gestion des environnements et l’apprentissage d’une politique de contrôle déterministe efficace. Concernant la tâche complexe de manipulation robotique impliquant un manipulateur robotique à 6 degrés de liberté, DCAC-v2 a réussi à apprendre une politique opérationnelle même en présence de délais extrêmes, contrairement à DCAC qui a rencontré des difficultés pour résoudre cette tâche.
References
- [1]A.R. Mahmood, D. Korenkevych, B.J. Komer, J. BergstraSetting up a reinforcement learning task with a real-world robotProceedings of 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems, IROS, Madrid (2018), pp. 4635-4640Google Scholar
- [2]F. Fuchs, Y. Song, E. Kaufmann, D. Scaramuzza, P. DürrSuper-human performance in gran turismo sport using deep reinforcement learningIEEE Robot. Autom. Lett., 6 (3) (2021), pp. 4257-4264Finding PDF…CrossrefView in ScopusGoogle Scholar
- [3]Y. Ge, Q. Chen, M. Jiang, Y. HuangModeling of random delays in networked control systemsJ. Control Sci. Eng., 2013 (2013)8–8Google Scholar
- [4]E. Schuitema, L. Busoniu, R. Babuška, P. JonkerControl delay in reinforcement learning for real-time dynamic systems: a memoryless approachProceedings of RSJ International Conference on Intelligent Robots and Systems, Taiwan (2010), pp. 3226-3231Finding PDF…CrossrefView in ScopusGoogle Scholar
- [5]V. Firoiu, T. Ju, J. TenenbaumAt human speed: Deep reinforcement learning with action delay(2018)arXiv:1810.07286Google Scholar
- [6]T.P. Lillicrap, J.J. Hunt, A. Pritzel, N. Heess, T. Erez, Y. Tassa, D. Silver, D. WierstraContinuous control with deep reinforcement learning(2019)arXiv:1509.02971Google Scholar
- [7]S. Fujimoto, H. Hoof, D. MegerAddressing function approximation error in actor-critic methodsProceedings of the 35th International Conference on Machine Learning, Stockholm (2018), pp. 1587-1596View in ScopusGoogle Scholar
- [8]T. Haarnoja, A. Zhou, K. Hartikainen, G. Tucker, S. Ha, J. Tan, V. Kumar, H. Zhu, A. Gupta, P. Abbeel, et al.Soft actor-critic algorithms and applications(2018)arXiv preprint arXiv:1812.05905Google Scholar
- [9]Y. Bouteiller, S. Ramstedt, G. Beltrame, C. Pal, J. BinasReinforcement learning with random delaysProceedings of International Conference on Learning Representations, Virtual (2020)Google Scholar
- [10]D. Yarats, R. Fergus, A. Lazaric, L. PintoMastering visual continuous control: Improved data-augmented reinforcement learning(2021)arXiv preprint arXiv:2107.09645Google Scholar
- [11]Y. Tassa , Y. Doron , A. Muldal , T. Erez , Y. Li , DdL Casas , D. Budden , A. Abdolmaleki , J. Merel , A. Lefrancq , et al.Suite de contrôle DeepMind( 2018 )préimpression arXiv arXiv:1801.00690Google Scholar
- [12]B. Amos , S. Stanton , D. Yarats , AG WilsonSur le gradient de valeur stochastique basé sur un modèle pour l’apprentissage par renforcement continuApprentissage pour la dynamique et le contrôle , PMLR ( 2021 ) , pp . 6-20Voir dans Scopus Google Scholar
- [13]D. Silver , G. Lever , N. Heess , T. Degris , D. Wierstra , M. RiedmillerAlgorithmes de gradient de politique déterministesActes de la Conférence internationale sur l’apprentissage automatique , Pmlr ( 2014 ) , pp. 387-395Google Scholar
- [14]S. Tunyasuvunakool , A. Muldal , Y. Doron , S. Liu , S. Bohez , J. Merel , T. Erez , T. Lillicrap , N. Heess , Y. TassaDm_control : Logiciels et tâches pour la commande continueImpacts logiciels , 6 ( 2020 ) , Article 100022Voir le PDFVoir l’article Voir dans Scopus Google Scholar
- [15]G. Brockman , V. Cheung , L. Pettersson , J. Schneider , J. Schulman , J. Tang , W. ZarembaSalle de sport Openai( 2016 )préimpression arXiv arXiv:1606.01540Google Scholar
- [16]D. YaratsDmc2gym : interface OpenAI Gym pour la suite de contrôle DeepMind( 2022 )Dépôt GitHub, GitHubGoogle Scholar
- [17]A. Karamzade , K. Kim , M. Kalsi , R. FoxApprentissage par renforcement à partir d’observations différées via des modèles du monde( 2024 )préimpression arXiv arXiv:2403.12309Google Scholar
- [18]P. LiotetRetards dans l’apprentissage par renforcement( 2023 )arXiv:2309.11096Google Scholar
- [19]B. Xia , Y. Kong , Y. Chang , B. Yuan , Z. Li , X. Wang , B. LiangDEER : Un cadre résistant aux délais pour l’apprentissage par renforcement avec des délais variables( 2024 )préimpression arXiv arXiv:2406.03102Google Scholar
- [20]Z. Liu , Y. Song , Y. ZhangActeur-réalisateur-critique : un nouveau cadre d’apprentissage par renforcement profond( 2023 )arXiv:2301.03887Google Scholar
- [21]B. Chen , M. Xu , L. Li , D. ZhaoApprentissage par renforcement basé sur un modèle prenant en compte le délai pour le contrôle continuNeurocomputing , 450 ( 2021 ) , p . 119-128Voir le PDFVoir l’article Voir dans Scopus Google Scholar
- [22]Y. Sun , J. Xu , C. Chen , W. HuCommande de suivi optimale basée sur l’apprentissage par renforcement pour un système de lévitation d’un véhicule à sustentation magnétique avec délai d’entréeIEEETrans. Instrument. Mesures. , 71 ( 2022 ) , p. 1 – 13 , 10.1109/TIM.2022.3142059Google Scholar
- [23]B. Han , Z. Ren , Z. Wu , Y. Zhou , J. PengApprentissage par renforcement hors stratégie avec récompenses différéesActes de la Conférence internationale sur l’apprentissage automatique , PMLR ( 2022 ) , pp. 8280-8303Voir dans Scopus Google Scholar
- [24]T. Xiao , E. Jang , D. Kalachnikov , S. Levine , J. Ibarz , K. Hausman , A. HerzogRéfléchir en se déplaçant : apprentissage par renforcement profond avec contrôle simultanéActes de la Conférence internationale sur les représentations d’apprentissage ( 2020 )URL https://openreview.net/forum?id=SJexHkSFPSGoogle Scholar
