




Apprentissage par renforcement multi-objectif pour inciter de manière prouvée à l’alignement sur les systèmes de valeur
Points forts
- Le problème de l’alignement sur plusieurs valeurs peut être transformé en un programme linéaire.
- Notre méthode d’incitation aux comportements alignés fonctionne avec jusqu’à 8 valeurs.
- L’ordre des valeurs d’un système influence considérablement le comportement aligné sur ces valeurs.
Abstrait
Cet article aborde le problème de l’alignement des agents apprenants autonomes sur de multiples valeurs morales. Plus précisément, nous présentons les principes théoriques et les outils algorithmiques nécessaires à la création d’un environnement où l’agent apprend un comportement conforme à ces valeurs, tout en s’efforçant d’atteindre son objectif individuel. Pour résoudre ce problème d’alignement des valeurs, nous adoptons le cadre de l’apprentissage par renforcement multi-objectif et proposons un nouvel algorithme combinant des techniques d’apprentissage par renforcement multi-objectif et de programmation linéaire. Nous illustrons notre processus d’alignement des valeurs par un exemple impliquant un véhicule autonome. Nous démontrons que l’agent apprend à se comporter conformément aux valeurs éthiques de sécurité, de réussite et de confort, la réussite représentant son objectif individuel. Ce comportement éthique varie selon l’ordre de priorité des valeurs. Nous utilisons également un environnement multi-objectif synthétique pour évaluer le coût de calcul nécessaire à la garantie d’un apprentissage éthique lorsque le nombre de valeurs augmente.
Mots clés
- Alignement des valeurs
- Apprentissage par renforcement multi-objectif
- Éthique
1. Introduction
Le problème de garantir que les agents autonomes agissent en accord avec les valeurs humaines [1] , [2] devient primordial à mesure que les agents se généralisent dans notre société. Par conséquent, il est urgent de développer une IA éthique et digne de confiance [3], capable de respecter les valeurs humaines [4] , [5] dans divers domaines d’application émergents (par exemple, la robotique d’assistance sociale [6] , les véhicules autonomes [7] , les agents conversationnels [8] ).On observe un intérêt croissant, tant dans le domaine de l’éthique des machines [9] , [10] que dans celui de la sécurité de l’IA [11] , [12] , pour l’application de l’apprentissage par renforcement (AR) [13] afin de résoudre le problème complexe de
l’alignement des valeurs . Une approche courante dans ces deux communautés consiste à créer des environnements incitant à adopter des comportements éthiques. Ces incitations sont généralement introduites par des fonctions de récompense exogènes (par exemple, [14] , [15] , [16] , [17] , [18] . La spécification de ces fonctions de récompense repose sur des principes éthiques. Les récompenses sont ensuite intégrées à l’environnement d’apprentissage de l’agent grâce à un processus
d’intégration éthique . Cependant, dans toutes ces approches d’apprentissage, les principes éthiques sous-tendent une valeur morale unique. Il est largement admis en éthique que les sociétés humaines défendent de multiples valeurs morales, hiérarchisées selon leur importance relative (c’est-à-dire en considérant d’abord ce qui est le plus valorisé. Cet ensemble ordonné de valeurs est souvent appelé système de valeurs . À notre connaissance, garantir qu’un individu apprenne à se comporter conformément à un système de valeurs demeure un problème ouvert, bien qu’il s’agisse du cas le plus fréquent dans nos sociétés [20] .Dans ce contexte, notre travail vise à automatiser la conception d’
environnements éthiques incitant un agent à adopter un comportement conforme à un système de valeurs, tout en poursuivant son objectif individuel. Pour ce faire, nous assimilons cet objectif à la valeur morale de la réussite, intégrée au système de valeurs considéré et priorisée par rapport aux autres valeurs morales. De plus, nous adhérons au principe selon lequel « la fin ne justifie pas les moyens » et affirmons que la réussite doit toujours être subordonnée aux normes éthiques supérieures du système de valeurs (telles que, par exemple, la non-malfaisance).
Cet article aborde le problème de l’alignement des valeurs en proposant un nouveau processus d’intégration éthique dans un contexte d’apprentissage par renforcement. À partir d’un système de valeurs sociales initial donné, nous l’enrichissons d’abord en y intégrant la valeur morale de la réussite, qui englobe l’objectif individuel de l’agent, comme illustré dans
la figure 1 (en haut à gauche). Ensuite, notre intégration éthique structure l’environnement d’apprentissage, garantissant ainsi que l’agent sera incité à adopter un comportement éthique conforme au système de valeurs enrichi. Puisque nous considérons plusieurs valeurs, nous désignons l’intégration éthique d’un système de valeurs par l’expression « intégration éthique multivaluée » (IEMV), ou simplement « intégration éthique » par souci de clarté.
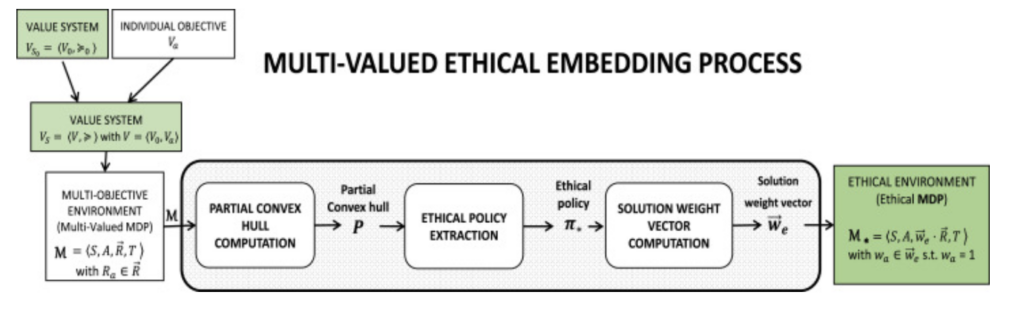
Fig. 1. Processus d’intégration éthique multivaluée (MVEE) pour la conception d’environnements (de gauche à droite) : calcul de l’enveloppe convexe partielle, extraction de la politique éthique et calcul du vecteur de pondération de la solution. Le processus prend en entrée un environnement multiobjectif.associé à un système de valeurs enrichiet renvoie en sortie un environnement éthique (à objectif unique)Les rectangles représentent des objets, tandis que les rectangles arrondis correspondent à des processus. La couleur verte indique qu’un objet donné est soit un système de valeurs, soit un environnement où l’adhésion à ce système de valeurs est encouragée. (Pour l’interprétation des références aux couleurs dans cette légende, veuillez consulter la version en ligne de cet article.)Nos contributions sont triples. Premièrement, nous formalisons le problème d’intégration éthique multivaluée dans le cadre des processus de décision markoviens multiobjectifs (MOMDP)[25] , [26] . Cette formalisation modélise les valeurs morales comme des objectifs éthiques au sein d’un processus de décision markovien multivalué , une instance de processus de décision markovien multiobjectif (MDP multiobjectif). De plus, notre formalisation ouvre la voie à notre définition des politiques éthiques , qui caractérisent le comportement d’un agent aligné sur un système de valeurs (c’est-à-dire en accord avec les valeurs morales et respectueux des préférences relatives à ces valeurs). Enfin, la prise en compte de plusieurs objectifs requiert des algorithmes spécifiques (plus complexes) pour un agent apprenant. Afin de faciliter l’apprentissage de l’agent, nous reformulons le problème d’intégration éthique comme la recherche du MDP monoobjectif qui intègre tous les objectifs éthiques (de sorte que les politiques optimales dans ce MDP soient éthiques). À cette fin, nous suivons l’approche dominante (par exemple [16] , [18] ) consistant à appliquer une fonction de scalarisation linéaire qui pondère les récompenses liées à chaque objectif éthique.Deuxièmement, nous proposons un nouvel algorithme pour résoudre le problème d’intégration éthique, qui généralise le processus d’intégration éthique à valeur unique présenté dans [19] . Notre nouvel algorithme combine les développements récents de l’apprentissage par renforcement multi-objectif (pour calculer les politiques éthiques) avec la programmation linéaire (pour calculer la pondération des objectifs éthiques). La figure 1 illustre cet algorithme, qui transforme un environnement multi-objectif d’entrée.dans un environnement éthique à objectif uniqueDans cet environnement à objectif unique, l’agent peut ainsi appliquer une méthode d’apprentissage par renforcement standard, et il est garanti qu’il sera incité à apprendre une politique alignée sur le système de valeurs en question.Troisièmement, nous illustrons notre processus d’intégration éthique en l’appliquant à un scénario de conduite autonome inédit (et simple), comprenant trois valeurs morales (sécurité, réussite et confort), la valeur de réussite représentant l’objectif individuel des agents. Ces valeurs ont été choisies en nous inspirant de celles décrites par Caballero et dans Nous montrons qu’un agent apprend à se comporter conformément à un système de valeurs grâce à un algorithme d’apprentissage par renforcement (Q-learning). De plus, nous étudions les différences entre les comportements alignés sur les valeurs qu’un agent apprendrait en fonction de ses préférences pour les valeurs considérées. Notre étude confirme que des comportements significativement différents émergent selon les préférences relatives aux valeurs au sein d’un système de valeurs. Cependant, les valeurs mentionnées ci-dessus ne représentant qu’un sous-ensemble de celles proposées par Caballero et al., nous analysons empiriquement le coût de calcul nécessaire pour garantir un apprentissage éthique lorsque le nombre de valeurs au sein d’un système de valeurs augmente. Pour ce faire, nous utilisons le générateur d’environnements synthétiques multi-objectifs de Notre analyse indique que notre algorithme d’intégration éthique parvient à réaliser l’intégration éthique d’environnements comportant jusqu’à huit objectifs et près de 10⁶ états en moins de cinq heures. Cependant, nous observons également que son coût de calcul croît exponentiellement avec le nombre de valeurs considérées.Enfin, il convient de noter que les travaux présentés dans cet article généralisent nos travaux initiaux et qui portaient sur le développement de fondements théoriques et d’outils algorithmiques pour la conception d’un environnement d’apprentissage garantissant une valeur morale unique. Par conséquent, les contributions de [19] et [31] doivent désormais être considérées comme un cas particulier de l’approche de conception d’environnements éthiques présentée ici.Le reste de cet article est organisé comme suit. La section 2 présente les notions de base nécessaires à l’apprentissage par renforcement multi-objectif et à l’éthique. La section 3 introduit formellement notre problème d’intégration éthique et le type d’environnements ciblés. La section 4 détaille notre algorithme de construction d’environnements éthiques. La section 5 présente l’analyse empirique de cet algorithme. Enfin, la section 6 aborde les travaux connexes et la section 7 conclut et propose des pistes pour les recherches futures.
2. Contexte
Cette section vise à présenter les notions fondamentales de notre approche de la conception d’environnements éthiques par apprentissage par renforcement.
- La section 2.1 introduit l’apprentissage par renforcement mono-objectif.
- La section 2.2 aborde ensuite l’apprentissage par renforcement multi-objectif. Enfin,
- la section 2.3 expose les concepts éthiques essentiels à la compréhension du rôle des valeurs morales dans notre approche.
2.1 . Apprentissage par renforcement mono-objectif
Dans l’apprentissage par renforcement mono-objectif (RL), l’environnement d’apprentissage de l’agent est formalisé comme un processus de décision markovien (MDP) [13] , [32] , [33] . Un MDP définit un environnement dans lequel un agent peut agir de manière cohérente pour le modifier et recevoir rapidement un signal de récompense après chaque action.
3. Formalisation du problème d’ intégration éthique multivaluée
Dans cette section, nous formalisons le problème de l’intégration éthique en considérant de multiples valeurs morales. Comme indiqué précédemment, notre objectif principal est de concevoir un environnement qui incite un agent à adopter un comportement éthique, c’est-à-dire conforme à un système de valeurs morales multiples. Comme mentionné dans la section 2 , la littérature éthique considère que les valeurs morales (également appelées principes éthiques) expriment les objectifs moraux qu’il convient de poursuivre.
- .Nous recherchons le vecteur de pondération minimal : deuxièmement, nous supposons qu’inciter l’agent par des récompenses éthiques a un coût pour le concepteur ou l’agent. Prenons comme exemple le problème de la fixation des sanctions routières. Une amende d’un million d’euros pour excès de vitesse garantira probablement le respect des limitations. Cependant, il est probablement préférable de rechercher la sanction minimale qui garantira le respect du code de la route. Ainsi,
- Nous cherchons à trouver le vecteur de pondération de la solution.qui a les poids les plus petits possibles (c’est-à-dire le vecteur de poids)avec les récompenses cumulées scalarisées minimales pour l’agent).
4. Résolution du problème MVEE
Cette section explique comment calculer un vecteur de pondération de la solution pour le problème d’intégration éthique multivaluée ( Problème 1 ). Ce vecteur de pondération nous permettra de transformer notre processus de décision markovien multivalué.dans un MDP (à objectif unique)en combinant les récompenses éthiques découlant du système de valeursen une seule récompense dans, l’environnement dans lequel l’agent apprend une politique alignée sur les valeurs.En bref, notre algorithme de résolution du problème MVEE, appelé algorithme d’intégration éthique , effectue les trois étapes suivantes (voir Fig. 1 ) :
- 1.Calcul de l’enveloppe convexe partielle d’un processus de décision markovien multivaluécontenant le sous-ensemble P de politiques optimales pour un certain vecteur de poids avec des poids positifs.
- 2.Extraction d’une politique alignée sur les valeurs π * de l’enveloppe convexe partielle P .
- 3.Calcul du vecteur de pondération de la solution : utiliser la politique π * extraite et alignée sur les valeurs pour trouver une pondérationdes récompenses danspour créer un environnement éthique à objectif uniquedans lequel toutes les politiques optimales sont garanties d’être alignées sur les valeurs.
5. Analyse expérimentale
Cette section poursuit un triple objectif : (i) illustrer notre processus de conception d’un environnement éthique (voir Fig. 1 ) ; (ii) illustrer la sensibilité de la politique apprise au système de valeurs choisi ; et (iii) réaliser une analyse empirique du coût de calcul nécessaire à la conception d’environnements éthiques. Face au manque d’environnements d’apprentissage par renforcement multi-objectifs de référence prenant en compte plusieurs objectifs éthiques, nous proposons un environnement de véhicule autonome novateur et simple. Cet environnement s’inspire des travaux de Caballero et al. [27] , [28] , qui offrent une taxonomie complète des objectifs éthiques dans le domaine des véhicules autonomes et étudient le problème selon une perspective de prise de décision non séquentielle, sans apprentissage. Dans notre environnement, nous considérons les valeurs morales de sécurité, de réussite et de confort afin d’illustrer notre approche et la sensibilité de la politique apprise aux différentes priorités de valeurs. Cependant, la taxonomie proposée par Caballero et al. indique qu’un agent aligné sur des valeurs doit potentiellement gérer des environnements multi-objectifs considérant plus de trois valeurs. Ainsi, pour analyser le coût de l’application de notre processus d’intégration éthique à des environnements dotés de systèmes de valeurs importants, nous avons recours à l’environnement synthétique WalkRoom [30] , l’un des rares environnements à objectifs multiples dans la littérature sur l’apprentissage par renforcement [52] .Le reste de cette section est organisé comme suit. La section 5.1 illustre l’application de notre algorithme d’intégration éthique à l’environnement des véhicules autonomes. Ensuite, la section 5.2 analyse le coût de calcul nécessaire pour garantir un apprentissage éthique dans un environnement synthétique à objectifs multiples, où chaque objectif correspond à une valeur.
5.1 . Environnement de voiture autonome à valeurs multiples
L’environnement de la voiture autonome à valeurs multiples est globalement caractérisé comme une route à deux voies sur laquelle une voiture autonome (l’agent apprenant) se dirige vers sa destination. La figure 2 (a) représente l’état initial de l’environnement : la voiture autonome est figurée par un cercle noir avec un C, et l’objectif par deux cases avec un X. La route présente des irrégularités (carrés violets) et des piétons (cercles noirs avec un P) que la voiture peut rencontrer. Les piétons ne peuvent traverser que les cases rouges (représentant les rues piétonnes interdites à la voiture) ou les cases bleues (représentant les passages piétons). La voiture autonome peut circuler sur les cases grises et bleues.
6. Travaux connexes
La littérature sur l’alignement des valeurs en IA se divise en deux grandes communautés : la communauté de la sécurité de l’IA [11] , [12] et la communauté de l’éthique des machines [9] , [10] . Bien que ces deux communautés communiquent rarement entre elles, notre travail vise à faciliter leur dialogue. Nous présentons d’abord un résumé des axes de recherche de chaque communauté, puis nous expliquons comment cet article établit des liens entre elles.
6.1 . Sécurité de l’IA
D’une part, la sécurité de l’IA vise à prévenir tout dommage que l’agent pourrait s’infliger à lui-même ou à autrui [11] en garantissant un comportement sûr. L’approche générale pour y parvenir consiste à contraindre [61] , [62] l’agent afin qu’il atteigne son objectif tout en évitant tout résultat dangereux . Ces résultats dangereux sont définis de différentes manières, par exemple en minimisant les effets secondaires de l’agent [63] , [64] ou en réduisant son impact sur l’environnement [12] , [54] . La littérature sur la sécurité de l’IA distingue également les situations où l’agent doit être protégé des résultats dangereux une fois déployé, et celles où il doit également être protégé pendant son entraînement [65] , [66] . Bien que ces travaux garantissent un comportement sûr de l’agent, ils ne permettent pas de garantir l’alignement sur une autre valeur, ni sur un système de valeurs composé de plusieurs valeurs, en se concentrant exclusivement sur la sécurité. Dans notre travail, le processus d’intégration éthique multivaluée permet de modéliser la sécurité comme l’une des valeurs du système de valeurs auquel l’agent est censé adhérer. Si, dans un système de valeurs donné, la sécurité est la valeur prioritaire, notre processus d’intégration éthique garantit un comportement optimal de l’agent en matière de sécurité. Si une autre valeur est prioritaire, le même algorithme d’intégration éthique conçoit un environnement différent, adapté aux priorités de ce système de valeurs.
6.2 . Éthique des machines
D’autre part, l’éthique des machines vise à développer des agents bénéfiques aux humains [2] . Là encore, différentes études définissent le terme « bénéfique » de diverses manières (voir une synthèse exhaustive des différentes définitions possibles du bénéfice d’un point de vue computationnel dans [41] , [42] ). Des efforts sont actuellement déployés pour définir et formaliser informatiquement les valeurs morales auxquelles un agent devrait adhérer [45] , [67] pour être bénéfique. Une autre piste de recherche vise à intégrer directement les différentes théories morales dans le processus de décision de l’agent [68] , [69] . La littérature étant encore loin de parvenir à un consensus sur la définition correcte d’un comportement éthiquement bénéfique, une approche agnostique alternative a émergé, capable de fonctionner en situation d’incertitude morale [70] . De même, nos travaux présentent un modèle applicable à tout système de valeurs, indépendamment des valeurs auxquelles l’agent devrait adhérer. Nous proposons une définition formelle de la structure d’un système de valeurs compatible avec l’apprentissage par renforcement. En particulier, notre définition du système de valeurs nous permet de concevoir informatiquement des environnements qui incitent l’agent à se comporter conformément à un système de valeurs donné.Il existe différentes manières de classer la littérature sur l’éthique des machines. L’une d’elles concerne les différentes méthodes d’inculcation des comportements éthiques : descendantes, ascendantes et hybrides, comme le montrent des études telles que [71] et [72] . En résumé, les méthodologies descendantes visent à formaliser les connaissances éthiques pour une intégration directe dans le comportement de l’agent, tandis que les stratégies ascendantes impliquent que les agents apprennent ces connaissances par eux-mêmes. Quant aux approches hybrides, elles combinent les méthodes descendantes et ascendantes.Plusieurs approches descendantes de formalisation des connaissances éthiques ont été explorées dans la littérature. Par exemple, Sierra et al. [45] ont formalisé les valeurs comme des préférences, tandis que Mercuur et al. [73] ont introduit une distinction conceptuelle entre valeurs et normes, les valeurs constituant une composante statique du comportement des agents et les normes un élément dynamique. De plus, Hansson et al. ont mené des études sur la relation formelle entre normes et valeurs [74] . Dans de nombreuses approches, comme les travaux de Liscio et al. [67] , les actions sont considérées comme moralement bonnes ou mauvaises selon leur contexte. De même, nos travaux définissent le degré d’alignement d’une action sur une valeur donnée en fonction de l’état environnemental actuel. Une autre approche descendante de formalisation des connaissances éthiques consiste à conceptualiser directement les théories morales en termes de processus de décision markoviens, comme dans les travaux de Nashed et al. [68] , [69] . Nashed et al. ajoutent une contrainte aux processus de décision des agents, les obligeant à suivre les principes d’une théorie éthique donnée. Ainsi, les agents apprennent à se comporter conformément aux contraintes de la théorie éthique choisie (utilitarisme de l’acte, kantisme, etc. [9 ]). D’autres approches considèrent des environnements où coexistent plusieurs valeurs morales et proposent de définir un système de valeurs comme un ensemble de valeurs morales assorties de préférences entre elles [27] , [46] , [47] , [48] , [76] . Nous appliquons ici une définition de système de valeurs inspirée de [48] et l’étendons au concept de
processus de décision markovien multivalué afin de traiter les problèmes de décision séquentielle. De manière générale, les efforts déployés pour formaliser les valeurs morales et les théories morales constituent une contribution significative au domaine de l’alignement des valeurs. En effet, les approches descendantes garantissent généralement qu’un agent qui y adhère adoptera un comportement éthique. Il est toutefois important de noter que ces approches impliquent souvent des coûts de calcul importants et peuvent, dans les scénarios les plus complexes, devenir impraticables. Par conséquent, il est largement admis que les méthodes purement descendantes ne suffisent pas à résoudre l’intégralité du problème d’alignement des valeurs, comme l’expliquent Arnold et al. [40] .
6.3 . Apprentissage par renforcement pour l’alignement
En adoptant une approche ascendante, l’objectif est d’apprendre à l’agent à adopter un comportement conforme aux valeurs éthiques, sans définir explicitement ce qui est éthique. Actuellement, la plupart des approches traitent ce problème d’apprentissage éthique par l’apprentissage par renforcement, suivant les travaux de Russell, Soares et Fallenstein, entre autres [1] , [2] . Plus précisément, l’apprentissage par renforcement inverse (IRL) [77] a été proposé comme solution potentielle au problème de l’alignement des valeurs. Dans l’apprentissage par renforcement inverse, l’agent ignore sa fonction de récompense. Il doit plutôt apprendre ses récompenses en étudiant la politique optimale. Appliquée au problème de l’alignement des valeurs, cette méthodologie permettrait à un agent de découvrir les valeurs morales des humains (la fonction de récompense cachée) en observant leur comportement (la politique optimale) [14] , [15] , [17] , [78] . Cependant, les approches d’apprentissage par renforcement inverse, et les approches ascendantes en général, présentent également plusieurs limites. Tout d’abord, nombre d’entre eux considèrent le problème de la spécification des récompenses comme équivalent au problème global de l’alignement des valeurs, partant du principe que l’agent n’a d’autre objectif que d’agir de manière éthique, sans tenir compte du fait qu’il puisse avoir ses propres objectifs. Ce problème a commencé à être abordé récemment, en conceptualisant l’alignement des valeurs comme un processus en deux étapes (spécification des récompenses et intégration éthique) qui doit prendre en compte les objectifs propres de l’agent (voir par exemple [16] , [17] , [18] , [19] , [31] ). En séparant ces deux étapes, l’environnement d’apprentissage de l’agent peut être modélisé de manière adéquate comme un environnement d’apprentissage multi-objectif (par renforcement).Toutes ces approches considèrent une combinaison linéaire de récompenses pour l’intégration éthique, à l’instar de notre approche. Cependant, aucune ne prend en compte le cas où l’agent pourrait devoir s’aligner sur plusieurs valeurs morales. Seuls les algorithmes de [19] et [31] abordent la question de la garantie qu’une combinaison linéaire de l’objectif individuel et d’une valeur morale unique incite effectivement l’agent à adopter un comportement éthique (c’est-à-dire conforme à cette valeur morale). Ce dernier axe de recherche, mené par Rodriguez-Soto et al., était initialement compatible uniquement avec l’apprentissage par renforcement tabulaire pour offrir des garanties théoriques. Il est intéressant de noter que cet axe a récemment été adapté aux algorithmes d’apprentissage par renforcement profond dans [79] . La méthodologie d’apprentissage par renforcement profond de Mayoral-Macau et al. permet d’automatiser la pondération des récompenses éthiques pour les systèmes de valeurs à valeur unique dans de vastes environnements comportant des millions d’états, au prix de la perte de toutes les garanties théoriques de la méthodologie de Rodriguez-Soto et al. Dans tous les autres travaux, il incombe au concepteur de l’environnement d’ajuster manuellement les récompenses.
7. Conclusion et perspectives
La littérature sur l’alignement des valeurs s’est concentrée sur l’alignement d’un agent avec une seule valeur morale et, à l’exception de [31] , a négligé les garanties relatives à l’apprentissage éthique de l’agent. Nous avons ici abordé le problème de la construction d’un environnement éthique garantissant qu’un agent apprenne une politique alignée sur de multiples valeurs morales.Nos contributions novatrices s’inscrivent dans le cadre des processus de décision markoviens multi-objectifs (MOMDP). Grâce aux MOMDP, nous formalisons la notion d’agent adoptant un comportement aligné sur des valeurs , c’est-à-dire suivant un système de valeurs multiple. De plus, nous proposons un algorithme permettant de construire un environnement éthique grâce à un processus d’intégration éthique multivalué . L’apprentissage d’une politique alignée sur des valeurs est garanti pour un agent dans un tel environnement, à condition qu’il utilise un algorithme d’apprentissage par renforcement convergeant vers la politique optimale.De plus, nous établissons une distinction entre les politiques alignées sur les valeurs et les politiques éthiques afin de souligner la nécessité de privilégier les normes éthiques supérieures aux intérêts individualistes. Par conséquent, garantir l’apprentissage des comportements éthiques implique également de choisir le système de valeurs (éthique) approprié. À titre de preuve supplémentaire, notre analyse empirique a démontré que la politique apprise dans un environnement éthique varie considérablement selon le système de valeurs choisi. Ainsi, les concepteurs de politiques éthiques doivent décider avec soin de la hiérarchisation des valeurs au sein du système de valeurs à intégrer dans un environnement éthique. Ils devraient collaborer avec une équipe d’éthiciens et d’experts du domaine qui évaluent les normes éthiques par une analyse approfondie du domaine et des études antérieures. D’un point de vue pragmatique, le concepteur s’interroge sur la manière d’analyser et de comparer différentes politiques alignées sur les valeurs. Dans cet article, nous présentons une méthodologie permettant de relever ce défi. Premièrement, le concepteur doit définir les systèmes de valeurs candidats à étudier. De plus, ils doivent définir un ensemble de métriques, appelées métriques éthiques , afin de quantifier le degré d’alignement d’une politique avec chaque valeur morale d’un système de valeurs (par exemple, les temps de trajet jusqu’à destination, les accidents, la conduite dangereuse et les irrégularités de la route dans notre étude de cas). Ensuite, le concepteur doit créer un environnement éthique par système de valeurs à l’aide de notre algorithme d’intégration éthique. Il doit ensuite procéder à l’apprentissage des politiques pour chaque environnement éthique. Enfin, le concepteur peut déployer les politiques apprises afin de mesurer l’alignement de chaque politique avec chaque valeur morale. Le résultat de ces simulations permettra au concepteur de comparer les politiques alignées sur les valeurs, d’éliminer celles qui ne sont pas admissibles (par exemple, les politiques entraînant des accidents et des situations de conduite dangereuse) et, finalement, de sélectionner le système de valeurs à déployer. Cependant, il convient de rappeler que pour que l’agent apprenne une politique éthique, le système de valeurs sélectionné doit nécessairement privilégier les normes éthiques les plus élevées (par exemple, la sécurité) par rapport à l’objectif individuel de l’agent.
Références
- [1]N. Soares , B. FallensteinAligner la superintelligence sur les intérêts humains : un programme de recherche techniqueRapport technique n° 8 de l’Institut de recherche sur l’intelligence artificielle (MIRI) ( 2014 )Google Scholar
- [2]S. Russell , D. Dewey , M. TegmarkPriorités de recherche pour une intelligence artificielle robuste et bénéfiqueAi Magazine , 36 ( 2015 ) , pp. 105 – 114 , 10.1609/aimag.v36i4.2577View at publisherVoir dans Scopus Google Scholar
- [3]R. Chatila , V. Dignum , M. Fisher , F. Giannotti , K. Morik , S. Russell , K. YeungIA fiableRéflexions sur l’intelligence artificielle au service de l’humanité , Springer ( 2021 ) , pp . 13-39Voir dans Crossref et Scopus Google Scholar
- [4]IEEE, Initiative mondiale de l’IEEE sur l’éthique des systèmes autonomes et intelligents, 2019, ( https://standards.ieee.org/industry-connections/ec/autonomous-systems.html ). Consulté le 31 octobre 2024.Google Scholar
- [5]E. Commission, Loi sur l’intelligence artificielle, 2021, ( https://eur-lex.europa.eu/legal-content/EN/TXT/?qid=1623335154975%26uri=CELEX%3A52021PC0206 ). Consulté le 29 juin 2021.Google Scholar
- [6]JP Boada , BR Maestre , CT GenísLes enjeux éthiques de la robotique d’assistance sociale : une analyse critique de la littératureTechnol. Soc. , 67 ( 2021 ) , Article 101726Voir le PDFVoir l’article Voir dans Scopus Google Scholar
- [7]SO HanssonLa structure des valeurs et des normesCambridge Studies in Probability, Induction and Decision Theory , Cambridge University Press , Cambridge ( 2001 ) , 10.1017/CBO9780511498466Google Scholar
- [8]J. Casas-Roma , J. ConesaVers la conception d’agents conversationnels pédagogiques éthiquement responsablesConférence internationale sur le calcul P2P, parallèle, en grille, en nuage et sur Internet , Springer ( 2020 ) , p . 188-198Google Scholar
- [9]H. Yu , Z. Shen , C. Miao , C. Leung , VR Lesser , Q. YangIntégrer l’éthique dans l’intelligence artificielleIJCAI ( 2018 ) , pages 5527 à 5533Voir dans Crossref et Scopus Google Scholar
- [10]F. Rossi , N. MatteiCréation d’une IA éthiquement encadréeProc. Conférence AAAI. Artif. Intell. , 33 ( 2019 ) , pp. 9785 – 9789 , 10.1609/aaai.v33i01.33019785Voir dans Scopus Google Scholar
- [11]D. Amodei, C. Olah, J. Steinhardt, PF Christiano, J. Schulman, D. Mané, Problèmes concrets de sécurité de l’IA, arXiv : 1606.06565 (2016).Google Scholar
- [12]J. Leike, M. Martic, V. Krakovna, P. Ortega, T. Everitt, A. Lefrancq, L. Orseau, S. Legg, AI safety gridworlds, arXiv : 1711.09883 (2017).Google Scholar
- [13]RS Sutton , AG BartoApprentissage par renforcement – Une introductionCalcul adaptatif et apprentissage automatique , MIT Press ( 1998 )http://www.worldcat.org/oclc/37293240Google Scholar
- [14]MO Riedl , B. HarrisonUtiliser des histoires pour enseigner les valeurs humaines aux agents artificielsAtelier AAAI : IA, éthique et société ( 2016 )Google Scholar
- [15]D. Abel , J. MacGlashan , M.L. LittmanL’apprentissage par renforcement comme cadre pour la prise de décision éthiqueTravaux de l’AAAI : IA, éthique et société , 92 ( 2016 )Google Scholar
- [16]Y.-H. Wu , S.-D. LinUne approche éthique à faible coût pour la conception d’agents d’apprentissage par renforcementActes de la conférence AAAI sur l’intelligence artificielle , 32 ( 2018 )Google Scholar
- [17]R. Noothigattu , D. Bouneffouf , N. Mattei , R. Chandra , P. Madan , R. Kush , M. Campbell , M. Singh , F. RossiEnseigner aux agents d’IA des valeurs éthiques grâce à l’apprentissage par renforcement et à l’orchestration des politiquesIBM J. Res. Dev. , PP ( 2019 ) , p. 6377-6381 , 10.1147 /JRD.2019.2940428Voir dans Scopus Google Scholar
- [18]A. Balakrishnan , D. Bouneffouf , N. Mattei , F. RossiIntégration des contraintes comportementales dans les systèmes d’IA en ligneProc. AAAI Conf. Artif. Intell. , 33 ( 2019 ) , p. 3 – 11 , 10.1609/aaai.v33i01.33013Voir dans Scopus Google Scholar
- [19]M. Rodriguez-Soto , M. López-Sanchez , JA Rodriguez AguilarApprentissage par renforcement multi-objectif pour la conception d’environnements éthiquesZ.-H. Zhou (éd.) , Actes de la trentième conférence internationale conjointe sur l’intelligence artificielle, IJCAI-21 , Organisation des conférences internationales conjointes sur l’intelligence artificielle ( 2021 ) , p. 545-551Voie principaleVoir dans Crossref et Scopus Google Scholar
- [20]D. CooperValeurs pluralistes et choix éthiqueSt. Martin Press, Inc. , New York ( 1993 )Google Scholar
- [21]WD RossLe bien et le juste : quelques problèmes d’éthiqueClarendon Press ( 1930 )Google Scholar
- [22]TL Beauchamp , JF ChildressPrincipes d’éthique biomédicale / Tom L. Beauchamp, James F. ChildressOxford University Press New York ( 1979 )Google Scholar
- [23]I. van de Poel , L. RoyakkersÉthique, technologie et ingénierie : une introductionWiley-Blackwell ( 2011 )Google Scholar
- [24]S. Schwartz, Un aperçu de la théorie Schwartz des valeurs fondamentales, 10.9707/2307-0919.1116 , Lectures en ligne en psychologie et culture, 2, pp. 11–20, Université hébraïque de Jérusalem (2012).Google Scholar
- [25]D. Roijers , S. WhitesonPrise de décision multicritèresConférences de synthèse sur l’intelligence artificielle et l’apprentissage automatique , Morgan and Claypool , Californie, États-Unis ( 2017 ) , 10.2200/S00765ED1V01Y201704AIM034http://www.morganclaypool.com/doi/abs/10.2200/S00765ED1V01Y201704AIM034Google Scholar
- [26]R. Rădulescu , P. Mannion , DM Roijers , A. NowéPrise de décision multi-objectifs et multi-agents : analyse et enquête basées sur l’utilitéSystèmes d’ agents multi-agents autonomes , 34 ( 2019 ) , p . 1-52Google Scholar
- [27]W. Caballero , R. Naveiro , D. RiosModélisation des préférences éthiques et opérationnelles dans les systèmes de conduite automatiséeDécis. Anal. , 19 ( 2021 ) , 10.1287/déca.2021.0441Google Scholar
- [28]WN Caballero , D. Rios Insua , R. NaveiroQuelques défis statistiques dans les systèmes de conduite automatiséeAppl. Stoch. Models Bus. Ind. , 39 ( 5 ) ( 2023 ) , pp. 629 – 652https://onlinelibrary.wiley.com/doi/abs/10.1002/asmb.2765Crossref Google Scholar
- [29]CJ Watkins , P. DayanApprentissage par renforcement (Q-learning)Mach. Learn. , 8 ( 1992 ) , pp. 279 – 292Google Scholar
- [30]M. Reymond , E. Bargiacchi , A. Nowéréseaux conditionnés par ParetoActes de la 21e Conférence internationale sur les agents autonomes et les systèmes multi-agents , AAMAS ’22 , Fondation internationale pour les agents autonomes et les systèmes multi-agents , Richland, SC ( 2022 ) , pp. 1110-1118Voir dans Scopus Google Scholar
- [31]M. Rodriguez-Soto , M. Serramia , M. López-Sánchez , J. Rodríguez-AguilarInculquer l’alignement des valeurs morales au moyen de l’apprentissage par renforcement multi-objectifEthics Inf. Technol. , 24 ( 2022 ) , 10.1007/s10676-022-09635-0Google Scholar
- [32]R. BELLMANUn processus de décision à la MrkovJ. Math. Mech. , 6 ( 5 ) ( 1957 ) , pp. 679 – 684Google Scholar
- [33]LP Kaelbling , ML Littman , AW MooreApprentissage par renforcement : une étudeJ.Artif. Int. Rés. , 4 ( 1 ) ( 1996 ) , pages 237 à 285Voir dans Crossref et Scopus Google Scholar
- [34]DM Roijers , P. Vamplew , S. Whiteson , R. DazeleyUne étude sur la prise de décision séquentielle multi-objectifsJ.Artif. Int. Rés. , 48 ( 1 ) ( 2013 ) , pages 67 à 113Voir dans Crossref et Scopus Google Scholar
- [35]P. Vamplew , R. Dazeley , A. Berry , R. Issabekov , E. DekkerMéthodes d’évaluation empirique des algorithmes d’apprentissage par renforcement multiobjectifsMach. Learn. , 84 ( 2011 ) , pp. 51 – 80 , 10.1007/s10994-010-5232-5Voir dans Scopus Google Scholar
- [36]A. Castelletti , G. Corani , A. Rizzoli , RS Sessa , E. WeberApprentissage par renforcement dans la gestion opérationnelle d’un système d’eauModélisation et contrôle des problèmes environnementaux ( 2002 )Google Scholar
- [37]S. Natarajan , P. TadepalliPréférences dynamiques dans l’apprentissage par renforcement multicritèreActes de la 22e Conférence internationale sur l’apprentissage automatique , ICML ’05 , Association for Computing Machinery , New York, NY, États-Unis ( 2005 ) , p. 601-608 , 10.1145 /1102351.1102427Voir dans Scopus Google Scholar
- [38]L. Barrett , S. NarayananApprendre toutes les politiques optimales avec de multiples critèresActes de la 25e Conférence internationale sur l’apprentissage automatique ( 2008 ) , p. 41-47 , 10.1145 /1390156.1390162Voir dans Scopus Google Scholar
- [39]K. Van Moffaert , A. NowéApprentissage par renforcement multi-objectif utilisant des ensembles de politiques dominantes de ParetoJ. Mach. Learn. Res. , 15 ( 1 ) ( 2014 ) , pp. 3483 – 3512Voir dans Scopus Google Scholar
- [40]T. Arnold , D. Kasenberg , M. ScheutzAlignement ou désalignement des valeurs – qu’est-ce qui permettra de responsabiliser les systèmes ?Ateliers AAAI ( 2017 )Google Scholar
- [41]I. GabrielIntelligence artificielle, valeurs et alignementMinds Mach. , 30 ( 2020 ) , p. 411-437 , 10.1007 / s11023-020-09539-2Voir dans Scopus Google Scholar
- [42]M. SutropLes défis liés à l’alignement de l’intelligence artificielle sur les valeurs humainesActa Baltica Historiae et Philosophiae Scientiarum , 8 ( 2020 ) , pp. 54 – 72 , 10.11590/abhps.2020.2.04Voir dans Scopus Google Scholar
- [43]E. Masonpluralisme des valeursEN Zalta , U. Nodelman (Eds.) , The Stanford Encyclopedia of Philosophy ( Été 2023 ) , Metaphysics Research Lab, Université de Stanford ( 2023 )Google Scholar
- [44]M. Serramia , M. López-Sánchez , JA Rodríguez-Aguilar , J. Morales , M. Wooldridge , C. AnsoteguiExploiter les valeurs morales pour choisir les bonnes normesActes de la 1re Conférence sur l’intelligence artificielle, l’éthique et la société (AIES’18) ( 2018 ) , p. 1-7 , 10.1145 /3278721.3278735Google Scholar
- [45]C. Sierra , N. Osman , P. Noriega , J. Sabater-Mir , A. Perello-MoraguesAlignement des valeurs : une approche formelleAtelier sur les agents responsables d’intelligence artificielle (RAIA) AAMAS 2019 ( 2019 )Google Scholar
- [46]TJM Bench-Capon , K. AtkinsonArgumentation abstraite et valeursArgumentation en intelligence artificielle , Springer ( 2009 ) , p . 45-64 , 10.1007 /978-0-387-98197-0_3Voir dans Scopus Google Scholar
