




L’homme, la machine et le marché : un traitement automatique du langage naturel appliqué à l’information sur la couverture énergétique
Points forts
- Cette étude examine la lecture algorithmique des informations financières en testant si les algorithmes de type « sac de mots » peuvent identifier les tendances des prix du marché des entreprises énergétiques couvertes.
- L’algorithme détecte une tendance plus marquée à la baisse des bêtas parmi les entreprises couvertes.
- L’algorithme est moins efficace que la classification humaine dans les applications plus complexes, comme l’identification des bêtas conditionnels modifiés des entreprises couvertes.
- Les mots clés présentant la plus faible divergence par rapport au travail humain ou les meilleures performances dans une application plus simple n’excellent pas dans une tâche plus complexe.
Abstrait
Cette étude examine l’efficacité de la lecture algorithmique en testant la capacité d’un algorithme à identifier les informations relatives aux couvertures de risque dans les rapports annuels des entreprises énergétiques. Au-delà de la pratique courante consistant à synthétiser des informations qualitatives issues du langage humain à l’aide d’algorithmes, nous introduisons une dimension d’évaluation supplémentaire en testant si ces algorithmes peuvent identifier les variations de prix du marché documentées dans la littérature sur les couvertures, comparant ainsi les performances de la lecture automatique et de la lecture humaine. Notre analyse textuelle, basée sur une méthode de comptage de mots-clés, révèle un taux de discordance de 21 % à 55 % par rapport à la lecture humaine. Malgré ces écarts, l’identification algorithmique parvient à détecter une tendance plus marquée à la baisse des bêtas parmi les entreprises couvertes. Cependant, les algorithmes sont moins performants que la classification humaine dans des applications plus complexes, telles que l’identification des bêtas conditionnels modifiés des entreprises couvertes. Nous constatons également que les mots-clés présentant la plus faible discordance avec le travail humain, ainsi que ceux ayant obtenu les meilleurs résultats dans une application plus simple, ne sont pas performants dans une tâche plus complexe.
ntroduction
Le langage utilisé dans les rapports d’entreprise véhicule des informations relatives aux prix, traditionnellement interprétées par des experts. Les méthodes informatiques automatisées offrent des alternatives économiques, mais leur exactitude doit être vérifiée. La plupart des études sur le traitement automatique du langage naturel appliqué à l’information financière n’apportent que des réponses partielles à cette question, car l’approche classique consiste à extraire une variable qualitative, ce qui masque l’évaluation de l’exactitude.
Une tendance récente est l’introduction d’algorithmes d’apprentissage automatique plus complexes (Bochkay et al., 2023), ce qui aggrave le problème car les chercheurs ne peuvent déterminer si la variable capture des informations contenues dans le langage ou d’autres aspects cachés de la structure des mots (Loughran et McDonald, 2020).Cette étude vise à évaluer la validité de la lecture algorithmique en comparant les performances de la lecture humaine et de la lecture automatique pour identifier des informations plus quantifiables : les opérations de couverture des entreprises. Dans un secteur relativement homogène où la couverture est fréquente, la littérature existante prédit que les cours boursiers des entreprises couvertes présenteront des profils différents de ceux des entreprises non couvertes. Ainsi, nous pouvons mesurer la performance d’une méthode d’analyse textuelle en examinant si les lecteurs humains ou algorithmiques sont capables de détecter des différences dans les fluctuations des cours. Nous pouvons également déterminer si les algorithmes peuvent potentiellement se substituer à la lecture humaine et dans quelles conditions ils sont performants.Nous nous intéressons aux pratiques de couverture des entreprises énergétiques cotées en bourse et répertoriées dans la base de données du Center for Research in Security Prices (CRSP) entre 1999 et 2020. Cet échantillon représente un ensemble relativement homogène, fortement exposé aux fluctuations des prix de l’énergie. Les entreprises ont facilement accès aux instruments de couverture, et les résultats sont observables sur les prix du marché. De même, les études sur la couverture analysent généralement le secteur de l’énergie (par exemple, Haushalter, 2000 ; Jin et Jorion, 2006)
.Déterminer si une entreprise pratique des opérations de couverture exige une analyse approfondie de ses rapports. Généralement, les informations relatives à la couverture figurent en fin de rapport annuel, où les entreprises expliquent leurs positions sous forme de textes ou de tableaux. D’une part, des chercheurs de niveau master analysent les rapports annuels des entreprises énergétiques et identifient les informations relatives à la couverture. D’autre part, notre méthode automatisée utilise des algorithmes basés sur des mots-clés. Nous analysons ensuite dans quelle mesure ces deux approches concordent avec les résultats de prix de marché établis dans la littérature sur la couverture, notamment les mesures bêta traditionnelles et les bêtas conditionnels associés au risque extrême.Nous constatons que les méthodes automatisées de sélection par mots-clés présentent des écarts non négligeables par rapport à l’interprétation humaine, avec des taux de discordance allant de 21 % à 55 %. Malgré ces écarts, les deux méthodes mettent en évidence une corrélation significative entre la couverture et la réduction des bêtas. Cependant, pour les variations de prix moins apparentes des bêtas conditionnels, seule la classification humaine permet d’identifier les effets.Nos résultats suggèrent que les algorithmes d’apprentissage automatique restent moins fiables pour détecter les comportements de couverture subtils. Nous constatons également qu’une faible divergence avec la lecture humaine ou de bonnes performances lors de tests simples ne garantissent pas le succès d’analyses complexes. Le mot-clé le plus performant dans notre analyse bêta conditionnelle n’est pas celui qui présente la plus faible divergence par rapport aux classifications humaines ni celui qui a obtenu la plus grande puissance statistique lors du test précédent.Ces résultats contribuent au développement d’approches plus économiques pour l’extraction de données financières à partir des publications des entreprises. Les tendances les plus évidentes, comme les coefficients bêta simples, ne nécessitent pas forcément d’algorithmes sophistiqués. Une approche possible pour les chercheurs est une approche par paliers : les méthodes d’apprentissage automatique sont utilisées pour les processus simples, tandis que l’intervention humaine est privilégiée pour les tâches plus complexes. Par ailleurs, il est risqué de supposer que des algorithmes performants dans une application le resteront dans une autre. Sans supervision adéquate, les algorithmes d’apprentissage automatique les plus complexes peuvent se révéler opaques dans les analyses économiques. Les théories économiques établies, les découvertes empiriques antérieures et l’impact potentiel du projet permettent de déterminer quelles tâches requièrent davantage de ressources humaines ou informatiques.
Extraits de section
Sélection des données et des échantillons
Nous identifions les entreprises énergétiques dans la base de données CRSP avec les codes de la Classification industrielle standard (SIC) 1311, 1381, 1382, 1389 et 2911, tels que définis dans le tableau 1. Les données de couverture sont extraites des rapports annuels, couvrant la période de 1999 à 2020.Le processus de classification humaine comporte deux étapes. Premièrement, des chercheurs diplômés examinent chaque rapport et en extraient le contenu pertinent. Deuxièmement, les auteurs évaluent ces extraits afin de déterminer si l’entreprise a eu recours à des opérations de couverture. Couverture non liée à l’énergie
Analyse bêta traditionnelle
Conformément à Tufano (1996) et Jin et Jorion (2006), nous estimons si les actions couvertes ont des bêtas plus faibles en utilisant le modèle de marché.
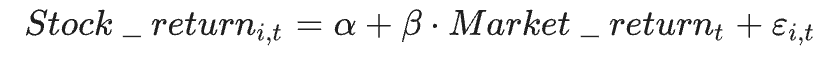
Pour estimer les bêtas des actions, le rendement du marché est le rendement pondéré par la valeur des actions issu de la base de données CRSP. Le rendement du marché pour les bêtas du pétrole est calculé à partir du prix du West Texas Intermediate (WTI). Les rendements du WTI sont basés sur les données de prix mensuelles disponibles auprès de la Réserve fédérale de Saint-Louis. Nous utilisons des estimations de bêta sur 60 mois.
Conclusion
Cette étude évalue l’analyse algorithmique de texte en comparant les classifications humaines et automatiques des opérations de couverture dans les entreprises énergétiques. Les machines reproduisent des schémas simples, comme la réduction des bêtas, même avec des écarts supérieurs à 20 %. Cependant, elles ne parviennent pas à détecter des effets plus subtils, tels que les bêtas conditionnels.Alors que les études précédentes ne comparent pas directement la lecture humaine aux approches algorithmiques, nous comparons les deux et identifions plusieurs points clés susceptibles d’améliorer l’analyse textuelle. Nous constatons que
Déclaration de l’IA générative et des technologies assistées par l’IA dans le processus d’écriture
Déclaration : Lors de la préparation de ce travail, les auteurs n’ont utilisé aucun outil de régénération par intelligence artificielle, à l’exception du correcteur grammatical Grammarly. Après utilisation de cet outil, ils ont relu et corrigé le contenu selon les besoins et assument l’entière responsabilité du contenu de l’article publié.
Références (10)
- A. Ang et al.Corrélations asymétriques des portefeuilles d’actionsJournal d’économie financière(2002)
- YP Chung et al.Qu’est-ce qui provoque la corrélation asymétrique des rendements boursiers ?Journal of Empir. Finance(2019)
- A. Kayhan et al.Historique des entreprises et leurs structures de capitalJournal d’économie financière(2007)
- T. Loughran et al.Intégration des informations pétrolières dans les prixAnalyse financière des revues internationales(2019)
- I. Babenko et al.Couverture des risques et clauses de prêt(2023)
- SR Baker et al.Mesurer l’incertitude de la politique économiqueQJ Économie.(2016)
- K. Bochkay et al.L’analyse textuelle en comptabilité : et après ?Contemp. Account. Res.(2023)
- De la Parra, D. 2022. La fermeté de la communication d’entreprise. Université de Caroline du Nord à Chapel Hill…
- M. Grinblatt et al.Marchés financiers et stratégie d’entreprise(2001)
